HP Z2 Mini G1a Workstation Review: Petite Power For Professionals

HP Z2 Mini G1a AI LLM Benchmarks
We spent a lot of time trying to get various AI tools working on the Ryzen AI PRO Max+ 395 in the HP Z2 Mini G1a. The short version is that many common local AI workflows still don't work on AMD hardware. So much time and development has gone into the NVIDIA CUDA side of things that it takes hacky workarounds to get reasonable performance in Windows—to the point that AMD's advice is often to install Linux (whether natively or through Microsoft's Windows Subsystem for Linux) and work there.That's not to say that our system was unable to work with AI, mind you. There exist a couple of tools that actually make it extremely easy to set up and run AI workloads on a system like this. For language models, which are useful in a local context for things like proofreading or summarization, you can use the LM Studio app that we've covered before.

In fact, thanks to the huge 128GB of memory, we were able to load and run OpenAI's GPT-OSS-120B, a very capable language model that offers similar performance to the company's proprietary o3-mini model in many tasks. There's a caveat to this, though, and it's that the configuration required to load this model leaves you with extremely little memory left over for the model's context window. Let us explain.
The HP Z2 Mini G1a as we received it has 128GB of RAM. This memory is shared between the CPU and GPU, but it's not truly "unified"; Windows still sees separate banks of CPU and GPU memory. You can configure the size of the RAM dedicated to the GPU, and you can also set it to 'auto', where the driver will automatically allocate more RAM from the system memory for the GPU as needed. This works great in games, but in our testing, it does not work correctly with LM Studio.

Not a big deal, right? Just set it to the maximum 96GB value. Well, that doesn't work correctly either. LM Studio wants to load the model into RAM before it loads it into VRAM, and so you need to have at least as much system RAM as you have VRAM, which makes 64GB the largest practical setting for this app at this time. We're given to understand that this isn't the case when using command-line tools like llama.cpp, but we're working with what we've got.
By default, LM Studio configures the model for a 4096-token context window, which is the amount of data it can consider when generating responses. This is small, and the model itself is likely to fill that context window in just a couple of responses. GPT-OSS-120B actually supports a 131,072-token context window, which is massive for a local model. You'd need much more RAM to make use of that feature, though. In our testing, setting the context above 8192 tokens caused it to bomb out with the above error message on the second or third prompt.
When it's working, though, it's honestly great. It's just like talking to ChatGPT, except the responses start instantly and come out quickly. LLM inference is light on data and heavy on compute, and on the Z2 Mini G1a, we recorded performance of around 24 tokens/second with GPT-OSS-120B. That's plenty fast enough for interactive use. If you could actually make use of the 96GB VRAM mode to enjoy the full context window, this could definitely be an excellent use case for this machine.
HP Z2 Mini G1a AI Diffusion Benchmarks
We also wanted to test AI image diffusion, which is a very different sort of workload from language processing. Dedicated image generation models are typically nowhere near as large as the largest LLMs, so it's quite possible to make use of them on consumer GPUs. However, there do exist larger AI image models, like Black Forest Labs' FLUX.1, which is fully capable of generating highly-realistic photographic images with almost no noticeable artifacts.
Normally, to do local AI image generation, you would use one of two very popular interfaces: the AUTOMATIC1111 Stable Diffusion WebUI and its derivatives (like Forge), or the popular ComfyUI, which is a nodegraph-based interface that offers a more visual approach to image generation. Unfortunately, neither of these interfaces are straightforward to get working on an AMD GPU in Windows 11. AMD itself recommends using a different interface, known as Amuse, seen below.

Performance with FLUX.1 is hampered by memory bandwidth.
Amuse is a very convenient application. Not only does it have a straightforward interface, but it also includes functionality right in the app to download compatible models. Thanks to AMD's involvement with the project, compatible systems (such as the Z2 Mini, here) can use a smart upscaler that runs on the XDNA 2 NPU, and there are even models that support running on the NPU directly. Of course, the NPU isn't as fast as the GPU, and the selection of models that are compatible with the NPU is more limited, so we will stick to the GPU for now.
Amuse fully supports Strix Halo and sees the full 96GB of RAM that is available to it, even if you don't have the system set to dedicate 96GB of RAM to the GPU. Frankly, it's quite a smooth experience to use. However, the app is highly censored, and will apply a destructive blur to any image results that it thinks are inappropriate. It also has generally poor support for models in the most popular .ckpt and .safetensors formats, requiring the HuggingFace "model.onnx" format instead. This is understandable given the limitations of the underlying frameworks, but nevertheless it does make the app less attractive to those experienced with AI image creation.
To see how the Radeon 8060S stacks up against desktop Radeon GPUs you're likely to find in a system at the same price point, we tested a variety of AI models on both the Z2 Mini G1a and a Radeon RX 7800 XT. Unsurprisingly, the much larger and more powerful Radeon card vastly outperforms the integrated GPU of the Ryzen AI Max+ PRO 395. However, you'll notice the discrete GPU actually failed three of our tests. That's because it only has 16GB of memory onboard, which isn't enough to load these larger models.
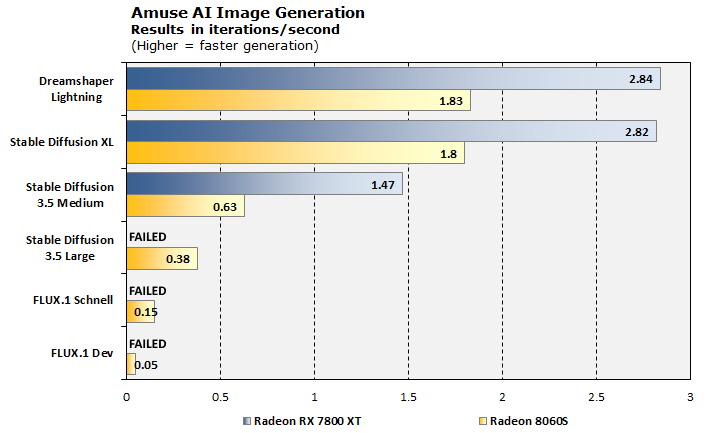
The Radeon 8060S cranks along with no real problem, although the generation speeds aren't outstanding at less than one iteration per second for the four more complex models. While this isn't too bad for FLUX.1-Schnell, because that model only requires a few iterations to produce a decent image, FLUX.1-Dev took more than ten minutes to generate a single image on the Radeon 8060S.
This really comes down to memory bandwidth. The Radeon 8060S has plenty of compute throughput, but the GPU itself is only active for a fraction of a second once every 10-15 seconds when using FLUX.1-Dev. The rest of that time is just shuffling data around in RAM, a process that would complete quickly on a large GPU with a massive GDDR or HBM local memory bus. On the relatively slow LPDDR5X on Strix Halo, it's nowhere near as fast.
For most purposes, Dreamshaper Lightning SDXL is capable of producing perfectly cromulent images in just a few seconds on both systems, and the more advanced models are really only needed if you want perfect text or hyper-realistic photos. It's cool to be able to use these bigger image models locally, but it's not always practical.
HP Z2 Mini G1a Geekbench AI Machine Learning Benchmarks
Of course, we ran some canned AI benchmarks, too. First up is Geekbench AI, which provides a straightforward look at how well a device handles a variety of AI-assisted tasks. This quick and easy test gives you a numerical snapshot of the CPU, GPU, and NPU's ability to power through real-world machine learning workloads, factoring in both speed and accuracy. The higher the score, the better the device's AI chops, whether it's image recognition, object detection, or natural language processing.Results are presented in three levels of numerical precision: single precision or FP32, half precision or FP16, and quantized or INT8. All results that the benchmark provides are geomean scores from multiple runs of each test workload, which is pretty convenient for us reviewers.
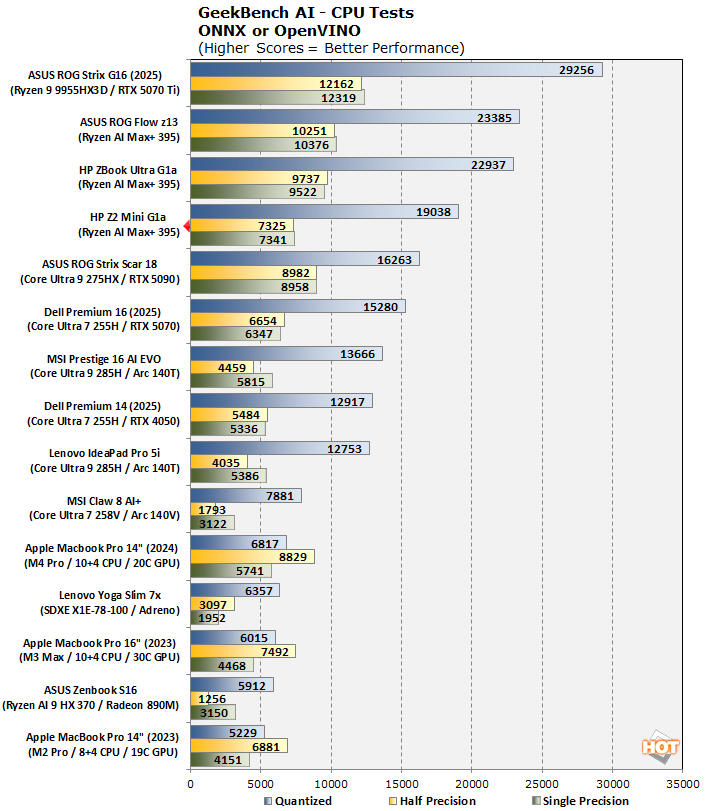
Starting off with the CPU tests, these results are sorted by INT8 performance, which Geekbench AI calls the 'Quantized' precision. The takeaway: sixteen Zen 5 cores is a hell of a lot of INT8 compute. However, the Z2 Mini G1a does once again come in well behind our other two Strix Halo systems. It still manages a third-place finish, but the gap is significant, and it persists across two different Windows installs.
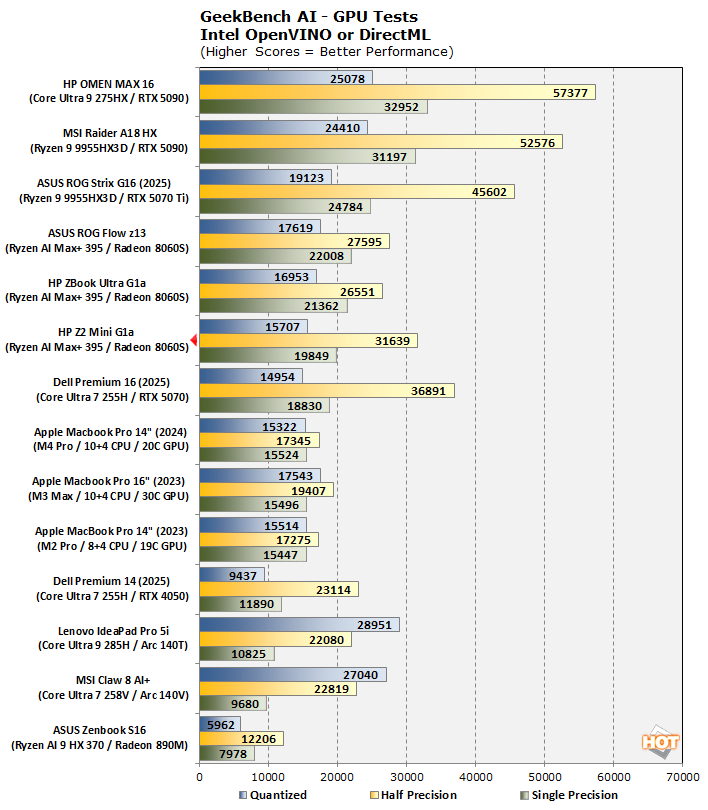
Next up we have GPU, and these results are sorted by the green "Single Precision" graph, since GPUs are generally very good at FP32 computations—although many of our GPUs are much better at FP16 math. Despite underperforming the other two Strix Halo machines in both INT8 and FP32, the HP Z2 Mini G1a somehow explodes past the other two in FP16, which is confounding. All three manage to offer superior DirectML performance to the GeForce RTX 5070 in the Dell Premium 16, which is interesting.
As far as NPU results go, well, there aren't any. Geekbench AI still doesn't support the XDNA 2 NPU in Strix Halo, so we don't have anything to show you here. It's worth mentioning, though, because this is somewhat representative of the AI experience on NPUs, and particularly on AMD NPUs. Things are improving somewhat, but NPUs are still not as widely supported in AI applications yet.
UL Procyon AI Computer Vision Benchmarks
However, UL's Procyon multi-benchmark *does* support NPUs, including AMD's, so let's have a look at that. The following is a look at how some of our machines do in this benchmark suite's AI Computer Vision benchmark. This test exercises the subject's ability to handle machine vision workloads, which you'll find in everyday tasks like webcam background blur, subject tracking, and eye gaze correction, for a just few examples.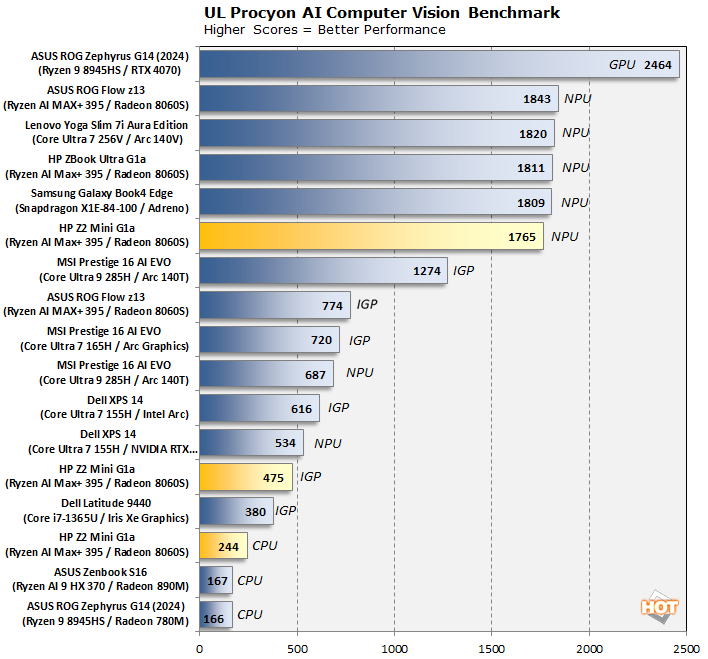
Here, you have benchmark results for the Ryzen AI PRO Max+ 395's three compute clusters: its 16 Zen 5 CPU cores, its 40 RDNA 3.5 compute units, and its sizable XDNA 2 NPU. The NPU is clearly the fastest at this specific type of work, although that's to be expected given that this kind of thing is exactly why it exists. Of course, big discrete GPUs are always going to be faster, but what's most curious is that the Z2 Mini G1a's integrated GPU scores considerably worse than the ASUS ROG Flow z13 based on fundamentally the same chip.
Ultimately, the story is much the same as with productivity. If you're buying one of these for AI, you should probably get it with Linux on it. That would allow you to use the speedy ROCm library to support AI workflows with the best performance possible on this hardware, and it also saves you about two hundred bucks.
This is absolutely not a gaming system, but it's fully capable of serving in that capacity. There are compelling reasons you might want to buy one of these for a gaming system, including its small size and excellent power efficiency, but there are also compelling reasons why you might not, some of which we're about to get into. We're going to start off our tests with 3DMark before diving into some real game benchmarks.
UL 3DMark Synthetic Gaming Benchmarks
3DMark has a wide variety of graphics and gaming related tests available. Usually, we prefer to run lighter tests on integrated GPUs and heavier tests on more powerful discrete GPUs, given the capabilities of the machine in question. However, considering that the Ryzen AI Max sort-of straddles the line between "integrated" and "discrete" horsepower, we really wanted to get clear comparisons against laptops, desktops, and similar integrated hardware. To that end, we ran three separate 3DMark tests: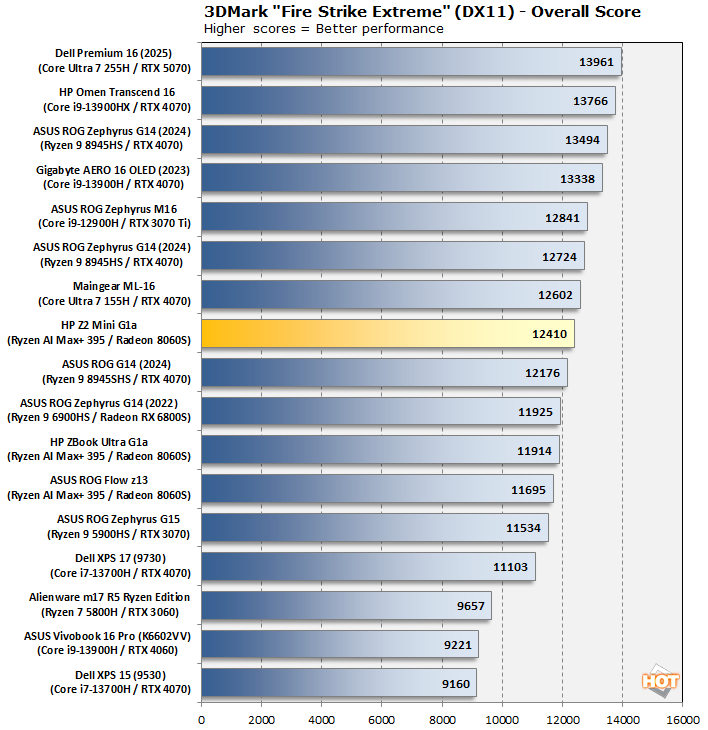
This first test shows comparisons in 3DMark Fire Strike Extreme against other laptop hardware. The Ryzen AI Max chips, despite being arguably desktop-class and implemented in a desktop form factor here, are first and foremost laptop processors. So how does it stack up? Surprisingly, slightly ahead of the Zbook Ultra G1a and the ROG Flow z13. We see performance very competitive with the GeForce RTX 4070 Laptop version, which is great.
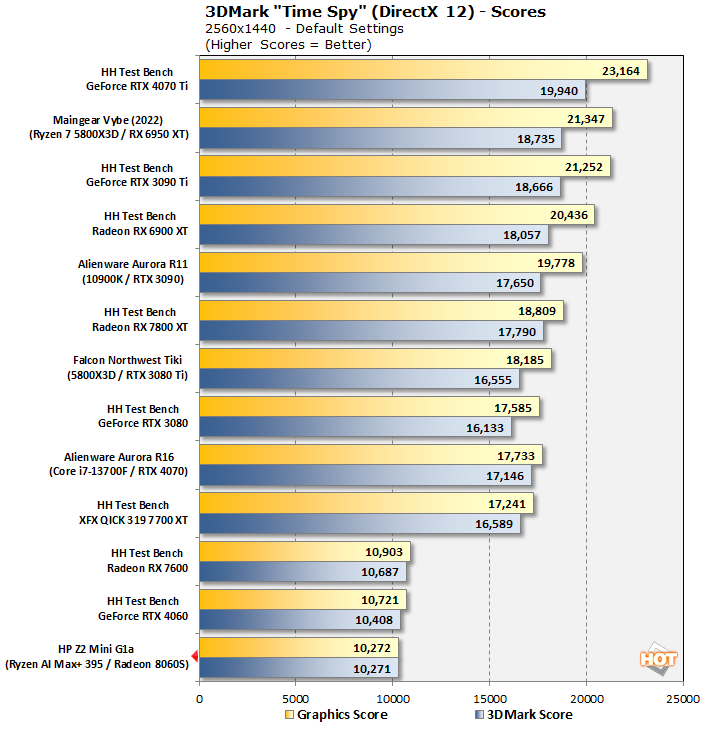
Meanwhile, this 3DMark Time Spy test compares against desktop machines, and it's here where you can really see that this is actually laptop silicon. The Z2 Mini G1a's Ryzen AI Max+ PRO 395 is broadly competitive against the Radeon RX 7600 and GeForce RTX 4060, but any faster desktop GPU clearly outruns this machine. A score of 10,272 is actually quite good performance in this benchmark in an absolute sense—although that says more about the age of the benchmark than anything else.
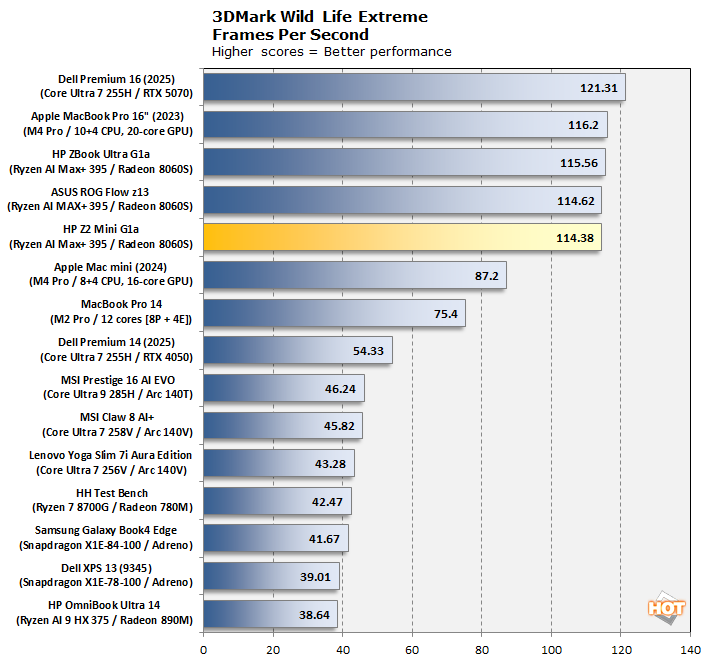
Finally, we wanted to compare in a cross-platform fashion against similar SoCs from Qualcomm and Apple. Because the otherwise-lightweight Wild Life Extreme benchmark runs in native 4K resolution, it's basically a memory bandwidth test, and one which the Z2 Mini G1a passes with flying colors. It basically matches the M4 Pro in the MacBook Pro 16", and isn't far behind a discrete GeForce RTX 5070 Laptop. Not bad.
Middle-earth Shadow of War DirectX 11 Benchmarks
Of course, we had to test some real games, too. Since we have comparison data for these titles, we went ahead and benched some familiar games on the Z2 Mini G1a. To test Middle-earth: Shadow of War, we set the visuals to the High preset and ran the in-game benchmark three times each in both 1080p and 2560×1440. The frame rates here are the average reported by the built-in benchmark, because the benchmark's "minimum" numbers are highly variable and don't seem to correlate to anything.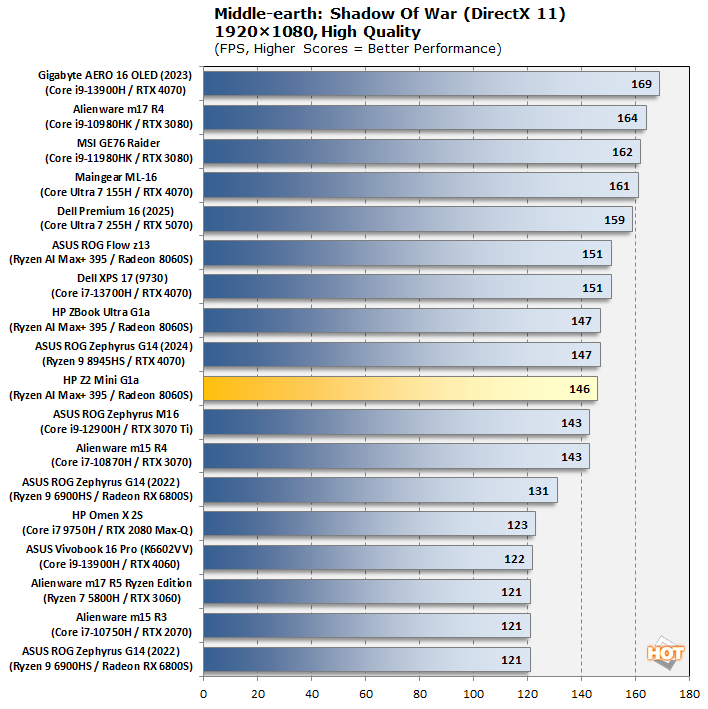
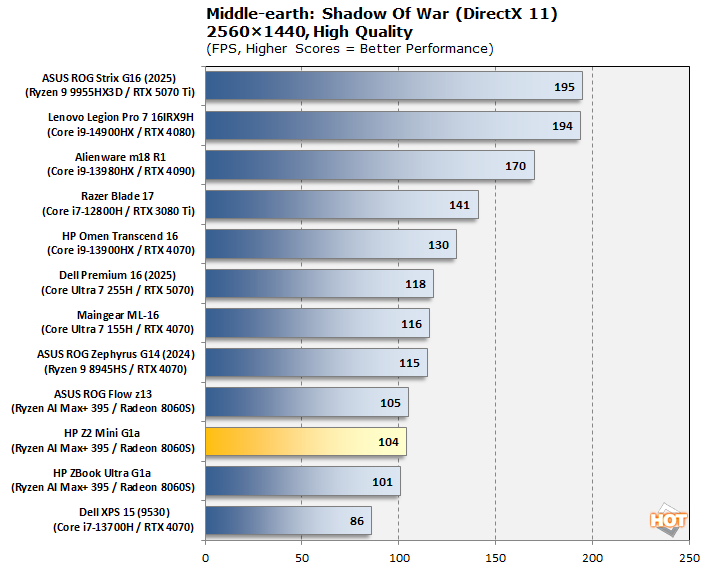
In this game, at 1080p where GPU pressure is lighter, we see a continuation of the trend from our productivity results, where the stability-focused Z2 Mini G1a lags behind the other Radeon 8060S-based systems slightly. However, the GPU performance is identical, so we see them all clustered together in 1440p.
Shadow Of The Tomb Raider DirectX 12 Benchmarks
The finale in the rebooted Tomb Raider trilogy, Shadow of the Tomb Raider is easily the best-looking of the bunch. It's also brimming with fancy tech, including for all three vendors' smart upscalers, ray-traced shadows, and even Tobii eye-tracking support. To test this game out, we turned the visuals up to their highest preset and tested at 1080p and 2560x1440.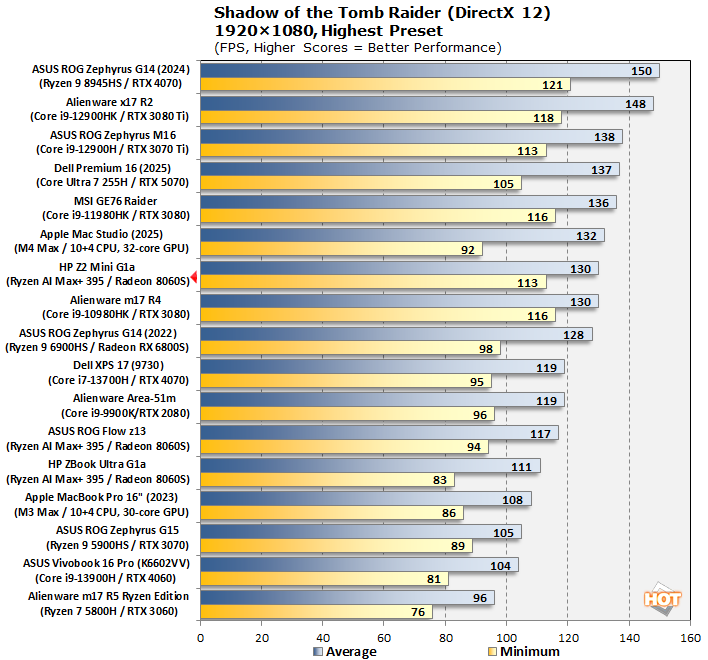
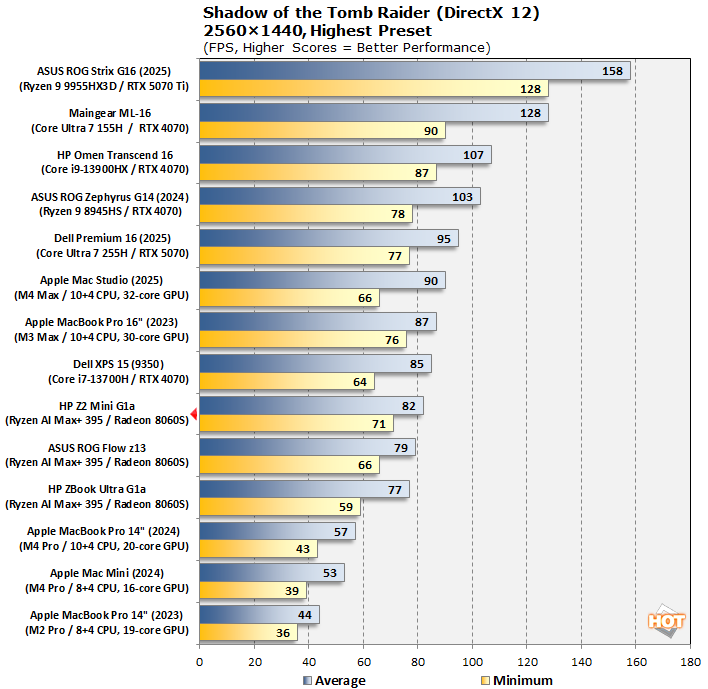
Apologies for the cluttered charts on this one, but it packs in not only x86 gaming laptops but also powerful Apple systems as well thanks to the existence of a native Mac port of this game (and our resident Mac maniac Ben Funk.) In this title, which more aggressively exercises both CPU and GPU, we see the Z2 Mini G1a pull away from the other Strix Halo machines, no doubt thanks to its high 160W power limit. Apple has the advantage at 1440p thanks to the Macs' super-wide memory buses, but in 1080p the Z2 Mini G1a can flex its superior software.
Marvel's Guardians of the Galaxy DXR Benchmarks
Marvel's Guardians of the Galaxy is an action-adventure game where you play as Star-Lord and lead the rest of the Guardians through various missions in a wide variety of galactic locales. The game's minimum requirements call for a Radeon RX 570 or GeForce GTX 1060-class GPU, but it also supports some of the latest graphics technologies, including DirectX Ray-tracing (DXR) and DLSS. We're testing it here with the settings slammed to the ceiling, including ray-traced reflections.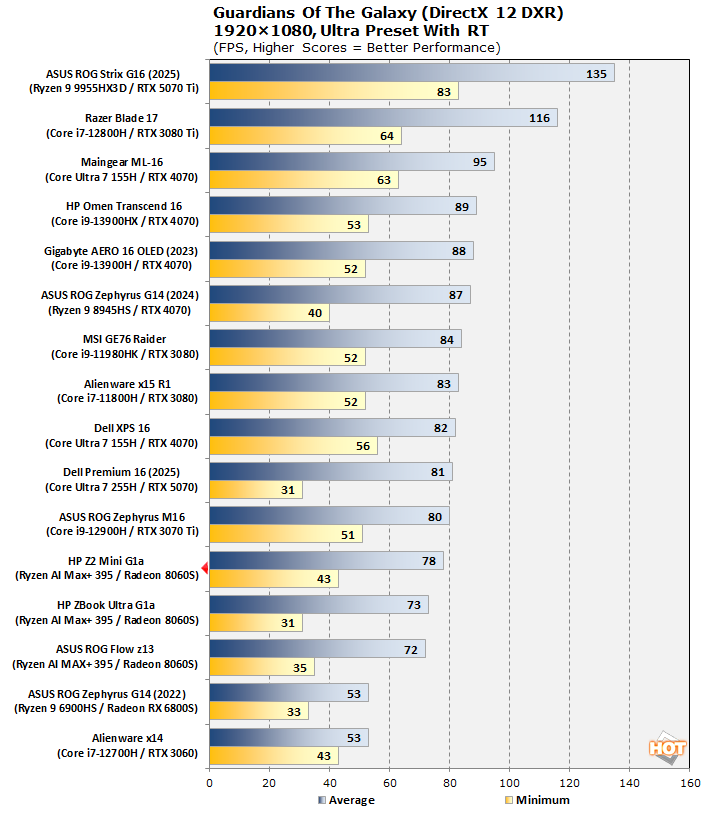
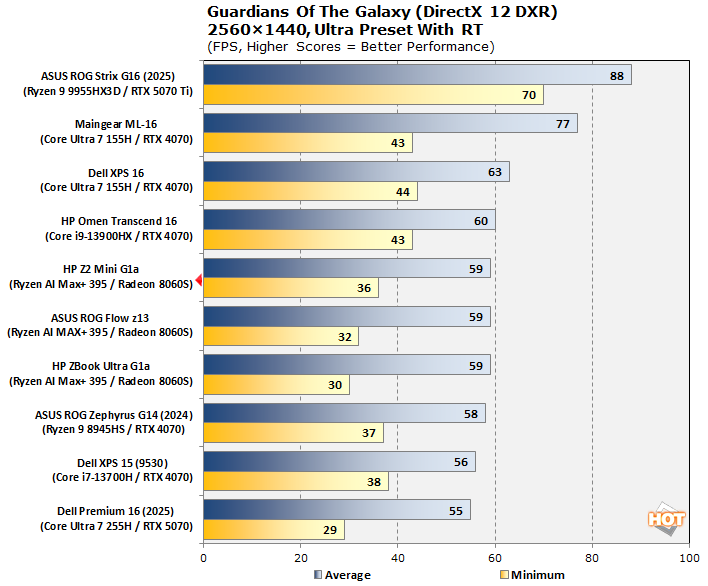
The addition of ray-tracing to our workload does force our Radeon 8060S GPUs to fall back a bit, but we think it's more about the extra memory bandwidth required than the GPU horsepower, and we think that because once the other cards start to become bottlenecked by memory bandwidth, the Radeon 8060S' relative performance actually rises. Framerates are still not far off the laptop GeForce RTX 4070 and RTX 3080, while considerably outpacing the mobile Radeon RX 6800S. All that while riding a 160W TDP max for both CPU and GPU; not bad at all.
F1 24 Formula One Racing Upscaling Benchmarks
Codemasters' annual officially-licensed F1 racing game carries forward the gorgeous custom ray-traced global illumination (RTGI) solution from F1 23 while improving texture quality and performance across the board. We normally use this game to show off the benefits of upscaling technologies, but this case is an interesting one, because the Ryzen AI Max+ 395 can barely run this game at these settings without upscaling. Check it out: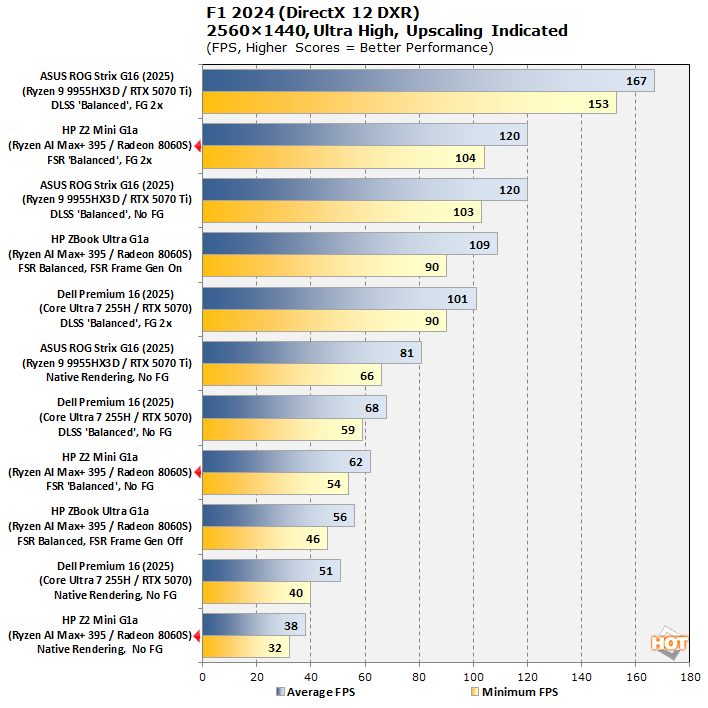
Upscaling does wonders with the Radeon 8060S. Despite the double-wide memory bus, it's still using relatively low-clocked 8-Gbps RAM compared to discrete graphics cards packing 20-Gigabit GDDR (or even higher speeds, on the new GDDR7 cards.) As a result, memory bandwidth is at a premium, and yet bandwidth requirements scale quadratically with render resolution. If you're OK with the visual effects from upscaling, it can help tremendously with game performance on this specific hardware.
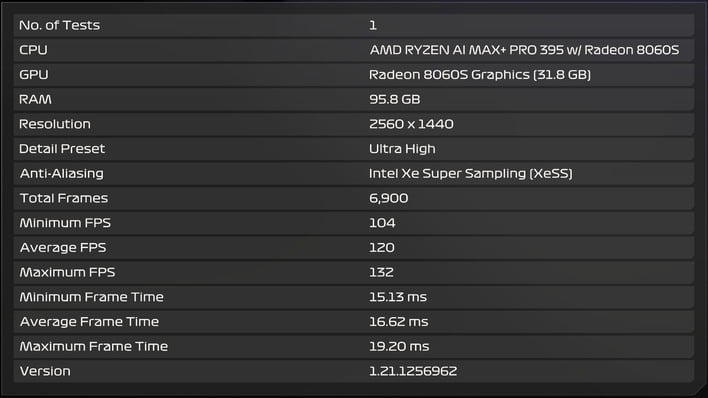
In fact, the memory bandwidth bottleneck results in some curious outcomes when using more advanced upscalers. Intel's XeSS typically offers better image quality results than AMD's FSR2/3, and on Strix Halo, it delivers exactly the same performance in F1 24, as seen above. But you can also make use of AMD's own FSR 4 for even better image quality, as seen below in Cyberpunk 2077:

This isn't officially supported, of course, but it's quite easy to set up thanks to the Optiscaler team, and the performance impact is less than you might think—around 2 milliseconds per frame at 1440p. We wrote up a guide on how to try FSR 4 on whatever games you like using an RDNA 3 GPU; you can check that by clicking the link.
Obviously, the Z2 Mini G1a is not a gaming machine, but as we've showed, it's perfectly competent in that role, even at 2560×1440 resolution. If you're using a high-refresh display, or if you're playing at 4K, you'll have to make judicious use of resolution upscaling, but it has the grunt to handle modern games.
Let's finish this review off by looking at power consumption, thermals, and noise.





