AMD Says It's Super Easy To Set Up Your Own AI Chatbot, Here's How


The setup process is really simple. In fact, it's so simple that we can lay it out for you in this paragraph. Just go download LM-Studio, and make sure to get the ROCm version if you have a Navi 21 or Navi 3x graphics card. (If you're not sure, that's the Radeon RX 6800 or better, or any Radeon RX 7000 card.) Run the installer, which will launch the application, then download a model. AMD recommends a couple that work well:

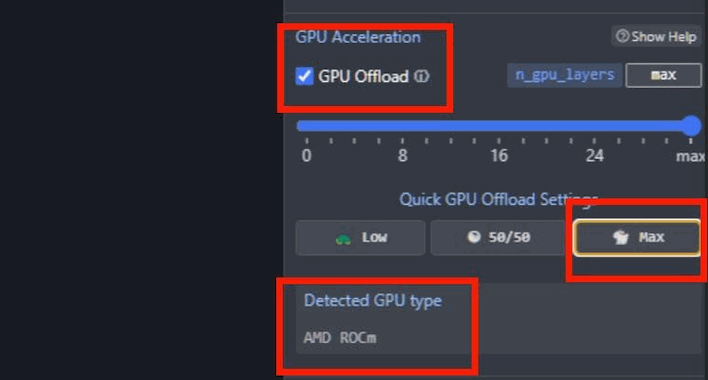
Once you have a model downloaded, click on the chat bubble icon on the left to start chatting with it. You may have to click on the purple bar in the top to select the model you downloaded first. If you're using the ROCm version, don't forget to open the settings and move that "GPU Offload" slider all the way to the right so that LM Studio uploads the entire LLM to your GPU's local memory, which will drastically improve performance.

If you're wondering why you'd bother doing this instead of simply talking to the more capable ChatGPT or Gemini services, it's primarily down to privacy and response time. Running an LLM on your local GPU guarantees a near-instant response time, and since everything happens on your own PC, there's no chance of anyone snooping on your conversation. You are also much less likely to run up against any guardrails placed on the model, meaning you could use the bot for whatever purpose your heart desires... within the limitations of its training data.
AMD also talks about using LM Studio on a "Ryzen AI PC". It's true; you can run LM Studio on a system with a Phoenix or Hawk Point processor. However, on those machines it will run on either the Zen 4 CPU cores or the integrated RDNA 3 GPU, as the llama.cpp project that LM Studio is based on doesn't support AMD's XDNA NPUs just yet. It also doesn't support Intel's NPUs either. It does look like progress is happening on both fronts though, so it may be the case that we have a real consumer application for NPUs soon.
