NVIDIA Jetson AGX Thor Tested: Blackwell Brings Physical AI to Life

|
NVIDIA Jetson AGX Thor Developer Kit - $3,499 As Tested
NVIDIA continues to innovate in all areas of the AI market, and its latest Jetson AGX Thor edge AI developer kit enables developers to design and deploy on NVIDIA's latest powerful Blackwell GPU architecture. |
|||

|

|
||
It's been a while since NVIDIA announced Project DIGITS and first discussed the Grace Blackwell chip that could fuel another AI revolution at the edge. That chip, NVIDIA's GB10, will power a number of platforms, including the often teased DGX Spark small form factor desktop PC.
However, what NVIDIA has recently announced, and what we'll be looking at in this hands-on deep dive, is a physically larger platform based a different Jetson T5000 module. This kit ships with a number of features that will help developers get up to speed on the company's latest Blackwell GPU architecture for forward looking edge AI applications. It's a beefier machine than the DGX Spark, and it has an appropriately beefy name, so let's meet the NVIDIA Jetson AGX Thor Developer Kit.
NVIDIA Jetson AGX Thor Developer Kit Specifications:
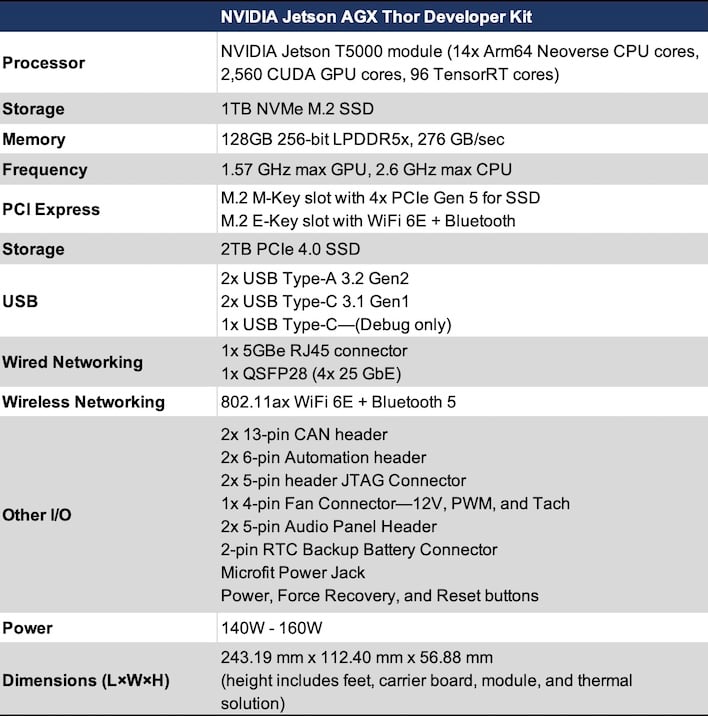
The Jetson AGX Thor developer kit sports NVIDIA's biggest, most powerful Jetson compute module to date, the Jetson T5000. This includes a Blackwell GPU with 2,560 CUDA cores, 96 fifth-generation Tensor cores, and a 14-core Arm Neoverse-based CPU all on a single chip. The CPU partition has 1MB of L2 cache per core, and a shared L3 cache weighing in at 16MB. All of that gets fed by a 128GB pool of LPDDR5x memory riding a 256-bit wide memory bus, which is good for 276 GB/sec of throughput.
Performance-wise, NVIDIA's new T5000 module has 2070 TFLOPs of FP4 throughput. Blackwell brings support for this new datatype, which has the benefit of more-or-less doubling performance. Since many edge inference AI use cases don't require a ton of precision, this does bring the benefit of running various models faster, if they've been optimized for the format. NVIDIA also rates it for 1035 TOPS at FP8. Those low-precision floating-point operations are still more costly performance-wise than the lowest INT8 that the Jetson AGX Orin Developer Kit was able to provide, and it topped out at 275 TOPS at its highest performance setting. As such, NVIDIA notes that peak performance results in Thor having a 7.5x performance advantage over the last generation, when taking advantage of NVFP4 for accurate low precision inference.

The Blackwell GPU architecture employed on Jetson AGX Thor also offers Multi-Instance GPU (MIG) support, which can slice the graphics processor into up to 7 partitions for running multiple models simultaneously. That's actually a really big deal, because while AI is an inherently parallel task, switching between models requires expensive context switching. With tons of GPU resources, even on an embedded edge computing device like the Jetson T5000, that means running an entire AI pipeline is a real possibility without the overhead previous generations experienced.
Finally, the last big architectural enhancement is that the memory is a giant pool of unified resources, much like the gobs of unified memory available in Apple Silicon Macs. That means that it doesn't matter if it's a task better suited to the GPU or the CPU, all of the 128GB of memory is available for processing. Compare that to large memory x86 devices like the AMD Strix Halo-powered HP Zbook Ultra G1a that we just reviewed, there's no static partitioning. Whether it's 96 MB or 96 GB, we shouldn't be running out of memory for any task with Jetson Thor.
The kit includes everything you need to get started: the Jetson AGX Thor Developer Kit itself, an AC adapter rated for 240 Watts, and a couple of USB cables useful for serial connections. The kit itself has a pair of USB-C connectors, both of which accept the AC adapter, along with two USB 3 Type-A ports, an HDMI 2.1 port, Gigabit Ethernet, and a 100 GbE port for networking lots of these devices together. It also has Wi-Fi 6E and Bluetooth for wireless connectivity, and 1 TB of storage useful for the Ubuntu 24.04 LTS installation along with many multiple GB of training data and containers.

Physical AI And The Need For Accelerated Machine Learning
Of course, most of the time, the memory in this machine is going to be dedicated to physical AI tasks. That is, AI powering things in the real world, like robotics applications. NVIDIA's got a pretty robust product stack, both on the hardware side as well as the software ecosystem. That just continues to be more and more true as the world learns about optimizing model performance and accuracy. Thanks to breakthroughs in optimizing the software stack, NVIDIA's AI hardware tends to get faster over time. Having both halves of the pie and making the software work on behalf of the hardware is what makes NVIDIA unique.But before we dig into that too much, we need to unpack what NVIDIA classifies as the whole physical AI process and the software that the company provides all along the way. Obviously the first thing you need to do in order to build a model for any task is to train it. And to do that, you need data. There is data in the real world, to be certain, but NVIDIA even augments that with synthetic data generation. We've talked at great length about Cosmos and Omniverse, which generates synthetic training data and turns it into visuals for robotic learning, like an AI playground.

Generating this data is step one of the process. This is done through its own sort of inference based on real world data. NVIDIA says it has achieved one of the milestones of AI, in that valid training data can be generated by other AI rather than by humans. You've got to have real data to start somewhere. However, rather than generate what could be billions of operations filmed at all angles. Cosmos can speed up the process of generating data. Simulating the real world through physics and materials, Cosmos generates the data points that show the model what to learn. Omniverse turns that data into realistic video through more generative AI, that the model can train on.
Step two is training. The model will use that data to build the its intelligence. It needs to know what it can predict will be the outcome of its actions, and that's what training is for. Incidentally, while LLMs can be trained on real data, there aren't too many robots at the scale NVIDIA imagines. NVIDIA says that means robotics training happens almost exclusively on generated data, and that will start to change as robots are deployed.
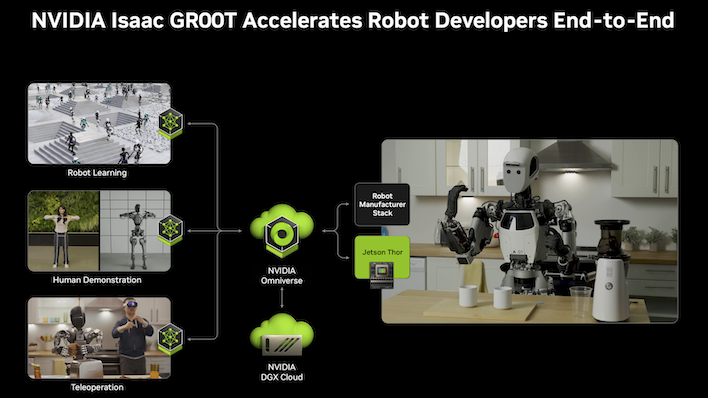
The third step after training is simulation. Robots in the real world are kind of dangerous if they're not controlled (cue timely sci-fi references) and they can be super expensive to build. There's less need to build robots before they're trained. The same tools that generate training data can also be used to simulate robots in synthetic space. Cosmos will interpret the robot's simulated actions, generating data as a result, and Omniverse renders that for humans to inspect.
Where Physical AI Meets The Real, Physical World
NVIDIA thinks that checking sensors 100 times per second is a bare minimum, and it would prefer polling at 1 kHz just to be sure that data is up to date. You don't want robots falling or gesticulating wildly, because that's where so much of the danger mentioned earlier originates. Models and hardware both have to be built with low latency in mind, because that sensor data comes in fast by necessity.Of course, just because a sensor sends a new input doesn't instantly necessitate a response from a model. Sometimes that data just needs to be gathered up so that changes over a short amount of time can be observed. Perception and planning will likely happen at a rate of around 30 Hz. That all includes self-localization (meaning, finding its current spot based on inputs), checking current grasp and motion, planning what to do next, and so on. With polling times of up to 1kHz that means as many as 300 inputs from each sensor need to be checked, and plans have to be finalized in a 33-millisecond window.

And then finally, high-level reasoning happens at around 10 Hz. That includes long-term planning (i.e., a robot folding boxes needs to observe the current state of the object and figure out the next steps), natural language recognition, and understanding what's going on in the environment around it. All of that stems from what the model is trained to do, what the sensors are telling the model about the current state, and any other parameters that developers feel the robot needs to consider.
All along the way, NVIDIA has software tools and hardware that it pushes as a complete, polished package. Along with Cosmos and Omniverse, the company also has Isaac, a robotics AI platform for building models that eventually lead to deploying robots controlled by NVIDIA hardware. Isaac includes three components. The GR00T models are general-purpose robot models for things like observing movement and performing actions with robotic arms. Isaac has its own robotics simulator that lives in Omniverse. And the Isaac ROS (Robot Operating System) is what accepts sensor input and feeds it into a model so that it can perceive the world around it and perform its tasks.

NVIDIA's Isaac Simulation Demo Impresses
One of the more interesting demos that NVIDIA built for developers to try is a "hardware-in-the-loop" scenario where its Isaac GR00T N1 foundation model runs on Jetson AGX Thor. The model controls a simulated robot, which is virtually deployed in Isaac Sim on the device. In this case, the robot is simulating a "nut pouring" task where it picks up a beaker full of nuts, dispenses a single nut into a bowl, and places it on a scale to observe its mass.
This is the first three steps in robot design in motion -- data generation, training, and simulation. NVIDIA says that with this workflow, a physical robot could be built from the simulated parts and perform this same task in the real world. NVIDIA captured a small set of demos in Isaac Sim, expanded up on them with Omniverse-based Isaac GR00T blueprints, and post-trained the N1 Vision-Language-Action model for the task. The company says it only took around 11 hours to generate more than 750,000 simulated trajectories, and it resulted in 40% higher performance thanks to adding simulated data to the real world observations.
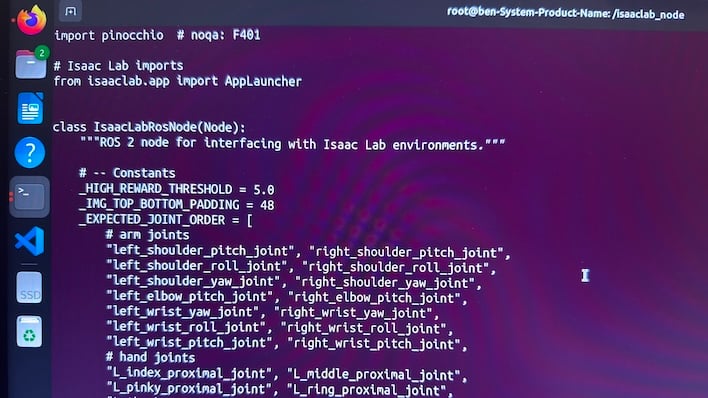
To test this out, we ran two different Docker containers, one on the Jetson AGX Thor Developer Kit and one on any old PC running Linux and sporting a GeForce RTX graphics card. In this case, we used a Core i7-13700K and a GeForce RTX 5080 on Ubuntu 24.04.3 LTS. On the Thor, we just start a container in Docker and then kickstart the model with a simple command. And then nothing happens, because the robot needs to receive signals from another machine. However, the robot's "brain" is up and running, although it's not receiving any sensory input so it can't start working.

Our Linux PC, which is running another Docker container, generates all the sensor data that the robot expects. Things like each joint's motor positions and movements, the nut that gets poured out of the vial and so on are all critical data streams. The simulated robot running on the Jetson Thor takes that sensor data and feeds it to the model, which then runs inference on that data and spits out what it should do next, which then gets sent back to our PC. Finally, Isaac Sim renders what the simulated robot is doing for observation.
This is a cool and interesting demo to be sure, and the workflow makes it obvious how NVIDIA envisions what developers need in order to make their own projects come to life.
While we haven't had the opportunity to really dig into NVIDIA's full robotics workflow, we do have our own AI workloads for other tasks, and it's time to see how the Jetson AGX Thor handles those. To find out more in our benchmark testing results, just turn the page...





