Items tagged with HPC

The U.S. Department of Energy is teaming up with NVIDIA and Oracle to build what's NVIDIA calls the DOE's largest AI supercomputer, part of a new public–private partnership meant to supercharge federally funded research. Announced at...
Read more...

AMD is a company that is certainly no stranger to building semi-custom processors. Indeed, the semi-custom unit of the company basically kept it afloat for a couple of years before the launch of Ryzen by supplying SoCs to Sony and...
Read more...

AMD disclosed a plethora of details during the Computex 2024 opening keynote regarding upcoming desktop and mobile processors in the Ryzen 9000 and Ryzen AI 300 families, respectively, along with a new dual-slot Radeon Pro W7900WS to...
Read more...

Although Intel and Argonne National Laboratory declared the Aurora supercomputer to be finally complete earlier this year, apparently it's not fully up and running just yet. It's only running with half of its 21,248 Xeon Max Sapphire...
Read more...

NVIDIA's CEO Jensen Huang donned his signature leather jacket to take the stage at SIGGRAPH 2023 and deliver the opening keynote for today's sessions at the famed rendering conference. Most of his talk today was about generative AI and how...
Read more...

AMD EPYC 9754 (Bergamo) and EPYC 9684X (Genoa-X) Processors AMD's latest Zen 4 EPYC server processors scale cache and optimized cores to amplify specialized HPC and hyperscale cloud workloads. Bergamo's 128 lean Zen 4c cores crunch...
Read more...

Intel's Data Center Max products are very impressive, but you may have had a hard time getting your hands on one even though they officially launched way back in November of last year. How come? Because they've all been going to Argonne...
Read more...

The International Supercomputing Conference, now known simply as ISC, starts today and runs through Thursday in Hamburg, Germany. All the big players are in attendance, but perhaps none are bigger than Intel. The company came full force at...
Read more...

Intel is launching its 4th Gen Xeon Scalable Processors (codename Sapphire Rapids) today, along with the Xeon CPU Max Series (codename Sapphire Rapids HBM) for datacenter customers. The company has been slowly disclosing information since...
Read more...

Lately, Intel faces stiff competition in what have traditionally been its strongest markets: data center and the enterprise. NVIDIA muscled in on Intel's territory a long time ago with its powerful GPU compute accelerators, but now the...
Read more...

Designing mobile CPU cores like those found in Qualcomm’s Snapdragon 8+ Gen 1 is only one aspect of Arm’s business. The company licenses designs for a myriad of enterprise use cases as well, which range from the datacenter to edge devices...
Read more...

Supercomputing changed in the late 90s. It used to be that the biggest and fastest computers were all completely custom jobs, with proprietary everything and exotic hardware running esoteric architectures. In the late-90s, someone figured...
Read more...

In case you haven't been following high-performance computing (HPC) news, NVIDIA is sort of ruling the roost lately. Its massively-parallel processing engines like GV100 and GA100 are the fastest chips around for computing many types of...
Read more...

For chip companies, bigger profit margins can be found in the data center market, and that's often where we see new innovations manifest first before trickling into the consumer space. To wit, we know AMD is prepping a Zen 3 refresh with...
Read more...

During its GTC 2021 keynote today, NVIDIA unveiled a new product for high performance computing (HPC) clients, its first-ever data center CPU called Grace. Based on Arm's architecture, NVIDIA claims Grace serves up 10x better performance...
Read more...

The name "Flashbolt" sounds like it could be a comic book superhero, or a spell you cast when running up against some ruffians in a role playing game. Neither of those things are what Samsung had in mind when launching Flashbolt, which is...
Read more...

The brain is the most complex organ in the body and the most difficult to unravel. Scientists have developed a variety of ways to better understand the brain, including the use of supercomputers. The world’s largest neuromorphic...
Read more...

Forget about running two graphics cards in SLI, imagine having 16 GPUs working in tandem to crunch through intensive workloads. That would be pretty awesome, right? It's also attainable, at least to certain audiences. NVIDIA today unveiled...
Read more...

Today’s opening keynote at the Intel Developers Forum focused on a number of forward-looking AI, deep learning, connectivity and networking technologies, like 5G and Silicon Photonics. But late in the address, Intel’s Vice President and...
Read more...

The Heterogeneous System Architecture (HSA) Foundation is making waves this week with the announcement of the HSA Specification v1.0. The HSA 1.0 spec is aimed at ushering in a new wave of heterogeneous computing devices that efficiently...
Read more...
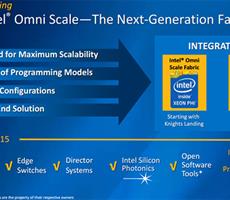
Intel today made a splash at the International Supercomputing Conference in Leipzig, Germany by revealing new details about its next-generation Xeon Phi processor technology. You may better recognize Xeon Phi by its codename, Knights...
Read more...

Like any smart company, NVIDIA is always looking for new markets and segments to dig into, and the company is doing just that with a push into high-performance computing (HPC). NVIDIA announced that its Tesla GPUs are being used to bring...
Read more...