AMD 4th Gen EPYC 9004 Series Launched: Genoa Tested In A Data Center Benchmark Gauntlet

At a high level, these processors are built similarly to 3rd Generation EPYC 7003 series processors. The platform consists of a central I/O Die (IOD), which is surrounded by multiple Core Complex Dice (CCD). In the EPYC 7003 series, the number of CCDs topped out at eight, but EPYC 9004 series processors can use as many as twelve. The CCDs are built on leading-edge 5nm process technology while the IOD employs more mature 6nm tech.

The number of cores per CCD is unchanged. Each CCD consists of two Core CompleXs (CCX) which house four cores each. This yields a total of eight cores per CCD. With up to twelve CCDs, this offers up to 96 cores (and 192 threads) in a fourth generation EPYC Genoa processor.

Zen 4 takes the Zen 3 foundation and improves it in several key ways. At the front end, the branch target buffers (BTB) have been expanded from 2 x 1k to 2x 1.5k L1 and from 2x 6.5k to 2x 7k L2. Integer and floating-point registers have likewise been expanded, as has the re-order buffer (ROB) for handling out-of-order instructions.

Zen 4 doubles the sizes of L2 cache to 1M per core from Zen 3. L3 cache is shared among the 8 cores of a given CCD. AMD also indicates that the architecture is more tolerant of cache misses from L2 to L3 and L3 to memory in turn, but over all misses should be improved. These tweaks should help keep the beast fed and improve overall throughput.

AMD pins IPC improvements over Zen 3 at about 14%. This largely comes from front end improvements (like the BTB expansion), but also cites branch prediction and load/store optimizations as key elements. The extra L2 cache is nice, but only contributes a small uplift across a geomean of various workloads. Specific cache and memory sensitive workloads will benefit more but may also be better suited by the upcoming GenoaX platform in turn.
AMD’s 4th Gen EPYC Platform Strategy
We want to take a moment to discuss how this all plays into AMD’s strategy, which seemingly contrasts with Intel’s. As we have seen on our early look at Sapphire Rapids, Intel is leaning very heavily into on-board dedicated accelerators. Accelerators provide an excellent boost for supported workloads, but may amount to wasted silicon for customers whose workloads do not leverage them. Instead, AMD is offering customers more general compute cores with a more measured approach to accelerators.
This is not to say AMD has abandoned accelerators entirely. EPYC 9004 processors have added hardware support for AVX-512, including instructions like VNNI for neural network uplift. Zen 4 achieves its AVX-512 implementation through double pumping 256b operations. AMD says this approach helps prevent clock speeds from dropping (which could affect mixed concurrent workloads) and helps with power and thermal overhead. There is performance tradeoff compared with a true 512b implementation, but AMD’s approach seems like a strong bet—particularly compared to not including AVX-512 acceleration at all.

AMD’s greater wager is the value proposition it can afford its customers through creating the best general purpose server CPU for a wide range of workloads—at least for Genoa. In the near future, we expect AMD to launch Bergamo for workloads that can leverage even higher threadcounts, Siena SKUs with lower core counts for cloud applications, and Genoa-X with embedded 3D V-Cache in the vein of Milan-X for particular memory and cache sensitive workloads. We will have more information about these other families as AMD makes it available.
4th Gen EPYC Platform Overview

Diving back into the new platform, these processors are primarily architected to be used in a dual processor (2P) configuration. That said, AMD has configured these in such a way that 1P systems are possible and we likely will see solutions from some manufacturers.
In the 2P setup, the processors can be configured to use 3 or 4 Infinity Fabric G links (xGMI). 4 links provide the best inter-socket throughput, but the 3-link option frees up 32 additional PCIe lanes if needed. The G links connect the “tops” of the processors but can alternately be configured to use two top G links and two bottom P links if the topology demands.

Link and connectivity options are plentiful. The platform can support xGMI, PCIe, CXL, and SATA serializer/deserializers but exact configurations will be up to platform partners to select. With the 3 link xGMI 2P configuration, the platform can support up to 160L + 12L, with the latter 12 lanes coming as 6 dedicated PCIe3 lanes per socket. With a 1P configuration, the xGMI links free up to still support 128L + 8L.
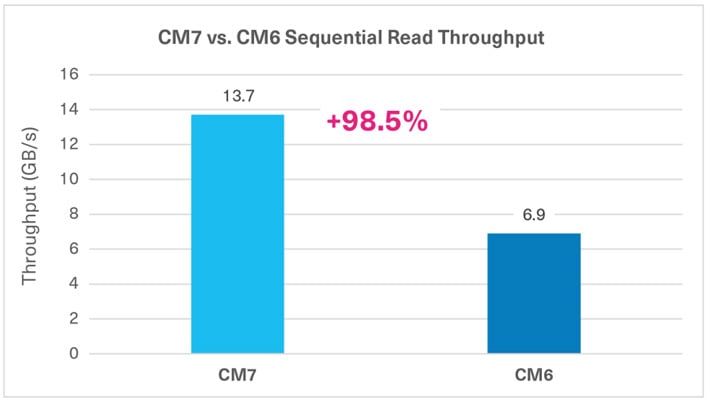
PCIe Gen 5 support is a very important conclusion. KIOXIA has highlighted how the PCIe Gen 5 interface allows its CM7 U.2 Enterprise SSD to achieve sequential read speeds approaching 14 Gbps. It is impressive to see manufacturers nearly saturating a x4 PCIe 5 link already, and will be important for shuffling around the immense amounts of data these processors need to chew through. KIOXIA used a Genoa system equipped with 32-core EPYC 9354 processors for its testing.
4th Gen EPYC Memory Configuration

Like the Ryzen 7000 Series, EPYC 9004 processors have made the leap to support DDR5 memory. This change brings higher bandwidth and better power efficiency, but it is not all advantages.

Fourth generation EPYC processors target DDR5-4800 with a theoretical peak bandwidth of 460 GB/s. AMD has improved single rank (x8) memory bandwidth relative to third generation EPYC by a significant amount. There is now only about a 4.5% penalty versus dual rank (x4), improved from an average of 25% loss.

EPYC 9004 series processors support up to 12 memory channels and can leverage a few different nodes per socket configurations (1, 2, or 4) depending on the workload to be optimized. It can scale down to just a single DIMM, but in any case, AMD is aiming to provide near the maximum amount of bandwidth regardless of installed capacity.

Current DDR5 memory does have greater latency than DDR4 memory, both in terms of cycles and actual timing. Total latency is around 13ns slower, only 3ns of which stems from the SoC itself. We expect DDR5 latencies to improve as it matures, but for most workloads it is a small price to pay for about double the throughput.

EPYC 9004 Series processors also support CXL, an open industry standard interconnect for memory expansion and accelerators which is cache-coherent. CXL is significantly faster than the PCIe links it is based on as a result. EPYC 9004 Series processors target CXL 1.1+ with a focus on memory expansion. The "plus" indicates support for certain CXL2.0 features, including persistent memory and RAS reporting. Users can opt to combine multiple CXL devices into a single interleaved NUMA node, if desired, and a NUMA node can also operate "headless" without any CPU assigned.
Zen 4 And Confidential Computing

AMD is continuing a commitment to security, particularly in regards to confidential computing. Confidential computing is a set of practices designed to protect data while it is in-use. Zen 4 still supports options like SEV-ES which encrypts CPU registers when the VM is inactive and memory encryption which is now upgraded to AES-256-XTS.
As side channel attacks have risen to infamy, which is particularly relevant when multiple VMs share a host. A malicious VM operator has the potential to probe the physical characteristics of the system to reveal secrets from concurrent guests or the host itself which it should not have access to. AMD has introduced SEV-SNP as an option for guests which checks to ensure it is the sole thread active on its core before processing, thus shielding against SQUIP style attacks. Indirect branch restricted speculation is also set to kick in for kernel mode (CPL0). This toggles on automatically as needed so software does not need to handle any additional housekeeping.
Scaling CCD Counts For AMD 4th Gen EPYC

While the top end Genoa SKUs will feature 96 cores, the architecture can scale down CCDs as needed to hit different price and performance targets. A key aspect of this scaling is that as CCDs are trimmed off, they maintain their logical GMI link. GMI is the interdie Infinity Fabric complement of xGMI which links CCDs to the IOD rather than node to node.

In other words, an eight CCD configuration (e.g. 64 cores) will populate the IOD’s GMI0 to GMI7 links, leaving the other four unused. Notably, AMD says that the CCDs will be physically rearranged in pairs together and closer to the IOD but retain the logical “gap” of the missing CCD.

SKUs north of 4 CCDs (e.g. 32 cores) use the GMI3-Narrow configuration with a single GMI link per CCD. With 4 CCD and lower SKUs, AMD can implement GMI-Wide mode which joins each CCD to the IOD with two GMI links. In this case, one link of each CCD populates GMI0 to GMI3 while the other link of each CCD populates GMI8 to GMI11 as diagramed above. This helps these parts better balance against I/O demands.
Genoa SKU Stack And Naming Convention
Like Ryzen Mobile, the AMD EPYC processors have received a new naming convention this generation in which every digit carries meaning. Unfortunately, the decoder wheel for Ryzen Mobile does not translate as these digits have different meanings.
The first digit indicates the product series. This is similar enough to the “model year” approach of Ryzen Mobile in that all the parts from this series will begin with a 9. The second digit indicates core counts, but itself needs to be decoded—a 3 indicates a 32C CPU, 5 for 64C, and a 6 indicates 84-96Cs. The third digit is an assessment of relative performance in the product series for a given core count, so bigger is better. The fourth digit indicates the generation, so we see a 4 indicating Zen 4 architecture. Finally, the trailing letter is a feature modifier which may indicate a -P for 1P configurations or an -F for frequency optimized parts.

AMD is launching 18 SKUs initially which fall under three broad categories which it calls Core Performance, Core Density, and Balanced and Optimized. Core Performance covers all of the -F SKUs which encompasses options from 16 cores to 48 cores with an emphasis on, well, per-core performance.

The Core Density segment entails all the other 48 core to 96 core options which utilize GMI-Narrow. The EPYC 9454/P SKUs overlap with the 9474F with 48 cores in either case, but the former has a milder TDP rating of 290W to the latter’s 360W. As may be expected, frequencies are lower as well by a few hundred megahertz.

The Balanced and Optimized SKUs trend similarly where core counts align with Core Performance counterparts. Where two SKUs share core counts within the Balanced and Optimized designation, like the 9354 and 9334, the former is configured with higher clocks and double the cache of the latter.
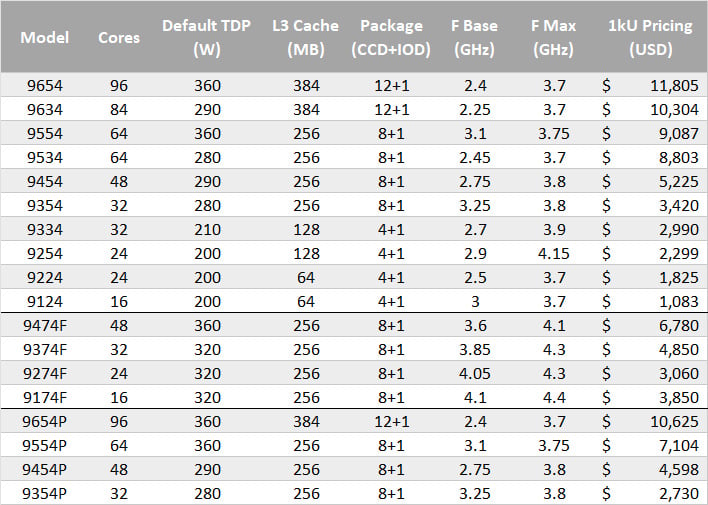
AMD provides typical cost per thousand pricing. While Intel Xeon Max products have just been announced, we do not yet have pricing for it, let alone head-to-head performance metrics. What we can observe generally is that Core Performance -F SKUs carry the highest costs per core. It rises to as much as $241 per core for the 9174F, though that is a serious outlier. It does offer the highest frequencies at the very least. Most of the other SKUs work out loosely in the neighborhood of $100 per core.
AMD’s 4th Gen EPYC Performance Claims
AMD provided a variety of internal benchmark numbers which it conducted against prior generation EPYC processors and Intel Xeon offerings. As Xeon Max (Sapphire Rapids) is not yet available, its listed comparisons are limited to Xeon Gold and Platinum processors already on the market.
Using SPECrate 2017 Integer throughput tests, AMD claims a 44-45% performance advantage over 3rd Gen Xeon competitors in iso core count configurations. Technically, the EPYC 9474F carries an eight-core advantage over the Xeon Platinum 8380, so keep that in mind.

Intel shows even stronger floating-point performance, to as high as an 81% uplift. We would be remiss to not call out the non-zero axis bars, though AMD is not alone in using this marketing tactic.

Moving on to more real-world applicable workloads, we will start with the Black-Scholes options pricing model. AMD shows its third gen EPYC 75F3 with 32 cores besting Intel’s 40-core Xeon Platinum 8380 by a small margin, but its 64-core EPYC 9554 CPU doubles the performance.

In Autodesk 3D rendering, AMD shows a 2.4x advantage for its 96-core EPYC 9654 CPU over the 40-core Xeon Platinum 8380. 96 cores is a 2.4x increase over 40 cores though, so the per-core performance is effectively identical. That said, Intel does not currently offer the ultra-high core counts that AMD does with Genoa, so it is still arguably a fair comparison with that context in mind.

The last of AMD’s comparisons we will share is for high performance compute workloads. In this iso core comparison, AMD shows 2x weather forecasting performance, 1.6x computational fluid dynamics performance, and 1.7x finite element analysis.

AMD’s pitch to customers is that EPYC servers can match performance with third gen Xeon systems while using 59% fewer servers and 47% less power. This not only increases potential rack density (power delivery permitting), but can also help reduce a company’s carbon footprint.
We will not leave you without some of our own testing, though. AMD provided us with its Titanite reference platform and three sets of processors which we will explore on the next page. Buckle-up, this is going to get very interesting, next...





