Sapphire Rapids 4th Gen Xeon Hands-On: Testing Intel's Bold Claims

Not satisfied to just shows these off in a controlled environment, Intel offered us the chance to put our hands on one of these beastly servers ourselves. When FedEx delivered the 2U rack-mountable chassis stuffed with the same configuration as our in-person meeting, we were able to recreate Intel's data center testing experience in our own lab, complete with tons of horsepower, screaming fans, and some noise-canceling headphones to keep us company.
Unfortunately, we can't disclose much more detail about this system; given its preproduction status, Intel is still not quite ready to announce model numbers, cache configurations, core speeds, and so on. We're certainly going to honor that request but don't fret, all will be revealed in due time. The good news is that there were also some tests we could run that weren't part of our initial demo, and Intel has allowed us to share those results with you here as well.
Setting Up An Intel Sapphire Rapids Xeon Server
We've seen some leaks, and we've seen these CPUs in person, but the real proof points lie in running benchmarks for ourselves. The fun thing about Intel's hands-on experience is that the server we received had no operating system. As if to prove that there's no magic software configuration, the company provided step-by-step instructions to replicate its results for ourselves. We got to install Ubuntu 22.04 and CentOS Stream 8, clone publicly-available Git repos, and execute all the tests we saw in person in September at Intel Innovation for ourselves. While installing an OS from scratch isn't the most glamorous task, we know our software setup will be the same publicly-available stack that the rest of the world uses. That means the following benchmark results we provide should be indicative of Intel expects performance to look like in real world deployments.We started with the latest long-term supported (LTS) version of Ubuntu Server, 22.04, and aside from enabling SSH and installing drivers for the pair of 100-Gigabit Ethernet cards there was no extra configuration. Some of the tests that Intel demonstrated require additional client hardware, and the clients were beefier than what we have on hand.
As such, Intel gave us remote access to a client/server pair, and we were able to first confirm the hardware and software installed on each and replicate those tests remotely. It's not quite the same as running these in our office, but we were comfortable with this compromise. So the NGINX, SPDK, and IPSec tests you'll see shortly were performed in that manner.

As part of the benchmark setup process, Intel provided purpose-built scripts, step-by-step instructions, and recommended BIOS settings for each. In between each test, we installed the requisite software packages, configured the BIOS as needed, and rebooted the system. Each test was run three times, and we took the median result for each task for our graphed results below. Our test system's configuration was identical to that which Intel demonstrated in September, so the results should be the same, if everything goes according to expectations.
For reference, our system's specifications are as follows: 2x pre-production 4th Gen Intel Xeon Scalable processors (60 core) with Intel Advanced Matrix Extensions (Intel AMX), on pre-production Intel platform and software with 1024GB of DDR5 memory (16x64GB), microcode 0xf000380, HT On, Turbo On, SNC Off. BIOS settings depended mostly on whether virtualization was required for each task, and so it was enabled and disabled as necessary.

New Benchmarks For Intel Sapphire Rapids 4th Gen Xeon
Before we get into a few remotely-performed tests, there are a couple of workloads we haven't seen Sapphire Rapids run yet, so let's start with those. First up is LINPACK, which we tested using Intel's optimized version based on its oneAPI math libraries. We were able to test with both an AVX2 codepath as well as AVX512.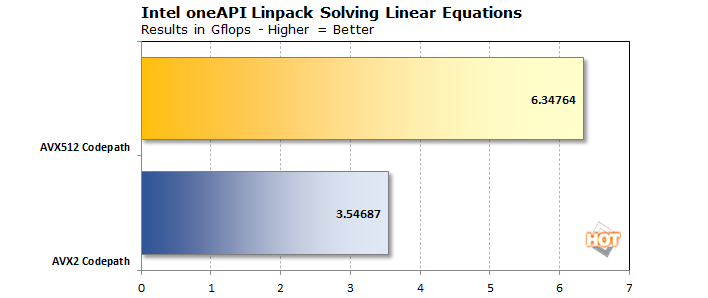
As you can see, the AVX512 version is just about 90% faster than AVX2. Not that 3.5 teraflops with AVX2 is pokey or anything, but with AVX512 extensions the platform was able to complete the same workload in 55% of the time. We all know that AVX512 is fast when a task can take advantage of it, and this certainly is one of those.
Next up we also ran a couple of molecular dynamic simulations. LAMMPS is an acronym for Large-scale Atomic/Molecular Massively Parallel Simulator, which is a classical molecular dynamics code with a focus on materials modeling. It runs on all kinds of platforms, including CPUs and GPUs. The CPU version takes advantage of AVX512, and is built against the oneAPI libraries.
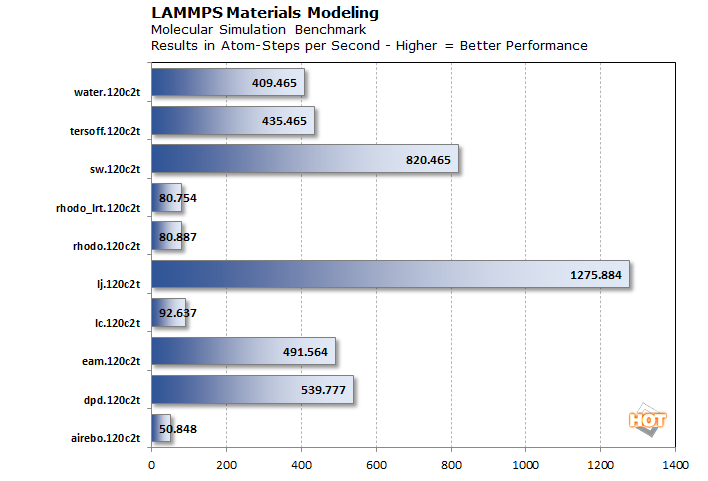
Unfortunately these results are a little out of context, as we don't have competing hardware or even previous-generation Xeons at our disposal currently. What we can tell you, however, is that these results are within a percentage point or so compared to what Intel showed us at its demo at Innovation 2022.
NAMD is another parallel molecular dynamics code designed for high-performance simulation of large biomolecular systems. It can scale up to and beyond 500,000 cores, so the 120 cores we have here should be flexed pretty hard. Just like LAMMPS, NAMD also uses AVX512 care of oneAPI. Rather than a chart, we get a single result: 3.25 nanoseconds per day of simulation. It seems that scientists would want a number of these systems working together, and that does put into context why the application can scale across 500,000 CPU cores or more. It's just an awful lot of math.
Last up is the ResNet50 Image Recognition benchmark. This uses version 1.5 of the ResNet50 machine learning model, which has some tweaks over the original model to improve recognition slightly and alleviate a bottleneck in downsampling. So in addition to more accuracy, it should also be somewhat faster than the original. All of that is important to note when running a benchmark, because these numbers are not directly comparable to version 1.
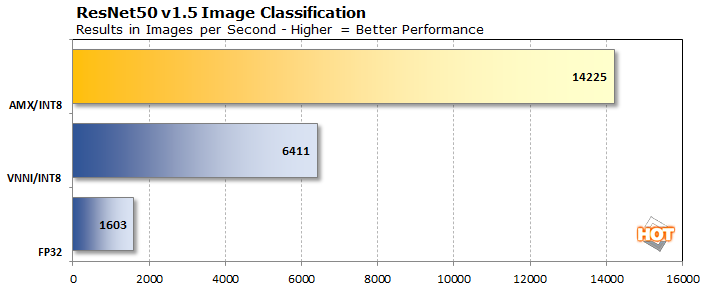
The three results above use 32-bit floating point math and 8-bit integer math, the latter of which is faster to execute in parallel and still has enough precision for AI tasks to not significantly change the results. Just making that switch and using VNNI, Intel's Vector Neural Network Instruction set, is enough to neatly quadruple performance in this benchmark. But then when the test moves on to using AMX, or Intel's Advanced Matrix Extensions, performance is more than doubled again, providing a 9x uplift in performance.
Testing Intel Sapphire Rapids Assertions: Compression And Database Workloads
Now that we've covered the previously-unpublished benchmarks, let's move onto confirming Intel's own benchmark numbers. As mentioned previously, we didn't have the physical access to an AMD Milan server, similar to what Intel used for its Sapphire Rapids comparisons, but we can at least validate whether Intel's claims hold up. There's enough publicly-available data around the web relating to performance on other platforms but we're just not comfortable comparing our own controlled work to others because there are so many variables. This means Intel's claims have to stand or fall on their own merit for now.There are two categories of these tests: those which need a second server as a client, and those that don't. We're going to focus on the latter since we needed to use Intel's remotely-accessible environment for a client.
We're going to start with QATzip, Intel's accelerated compression library. Compression technologies help keep the internet running at full speed. Text, especially HTML, CSS, and JavaScript, can be greatly compressed to reduce download times and allow servers to send data to as many clients as possible while conserving bandwidth. That compression often comes at a cost, however, in that it requires precious CPU cycles to deflate data in either a standard Gzip format or standard LZ4 blocks of compressed data contained in LZ4 frames.
That's where the QAT in QATzip comes in: Intel's Quick Assist Technology, which is the family name for several Xeon accelerator technologies, uses two methods to speed up the process. The first is Intel's ISA-L, or Intelligent Storage Acceleration Library. Compared to the standard ZLIB compression library's Gzip functionality, the performance promises to be more than 15 times faster. The second is using Intel's dedicated acceleration hardware for QATzip, which the company says should push performance even higher.
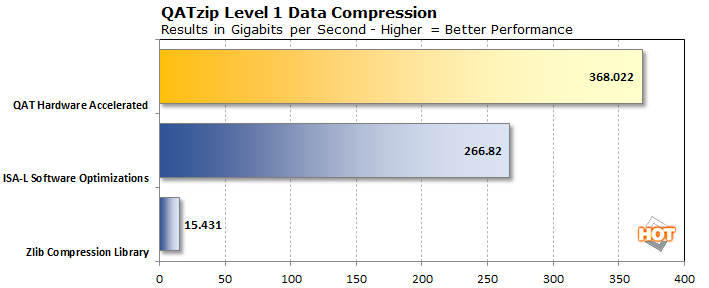
Remember that in Intel's own tests, the pair of 64-core Milan CPUs in the EPYC system actually won with Intel's own ISA-L library, and eight more cores was likely not going to make up the difference. However, employing Intel QAT acceleration built into our server did two things: not only was performance just short of 40% higher, but the benchmark reported that it wasn't using all 120 cores. The server was actually utilizing just four cores, which we could verify by using the top command in a second SSH terminal window. That means that the rest of the CPU cores in our system could get busy doing other things. Looking back at Intel's numbers, we can also see that using the Quick Assist Hardware is fast enough to surpass current gen AMD EPYC system, too.
Next is RocksDB, which is a data indexing storage system. Important (and famous) competitors include Elasticsearch and Amazon's OpenSearch. The idea behind these key/value indexing systems is to make huge datasets searchable with minimal latency. RocksDB got its start indexing Facebook and LinkedIn users, posts, job listings, and so on. It's also used as the storage method for popular SQL databases like MySQL and NoSQL databases like MongoDB and Redis. These tools are important for keeping the internet searchable quickly. Intel's QAT accelerates data compression and aims to speed up searching and finding records.
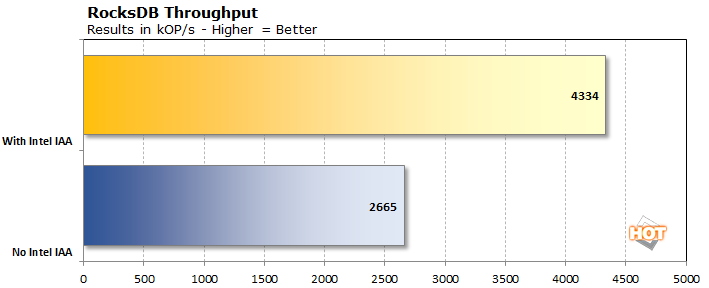
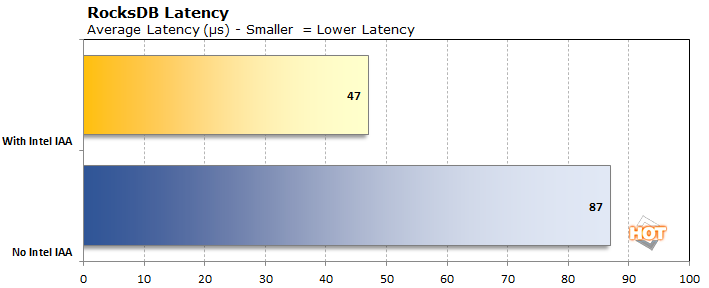
The "No Intel IAA" result above uses the Zstandard real-time compression algorithm. The task is an 80/20 workload (meaning 80% of the operations are read operations) hovered around 100 microseconds in latency and could handle around 2,500 kOP/s. Using Intel's In-memory Analytics Accelerator (IAA), which is part of Quick Assist Technology, the latency dropped in half to 48 microseconds and it pushed 4,291 kOP/s. That's basically identical to the numbers Intel published, showing that again QAT is really handy in another common server workload. IAA didn't accomplish this with a huge storage footprint, either; the sample dataset was around 43 GB on the disk with ZSTD, while the IAA version was only slightly bigger at 44.6 GB. Of course, that data was loaded into the huge 1 TB of RAM in the system to keep latencies as low as possible, but persistence is mandatory unless you want to rebuild an index with each reboot.
Next up it's time to run our client/server tests, which for our purposes means a remote SSH session with another Sapphire Rapids server. Then we'll wrap up everything we've seen.