Future Intel CPUs May Dump Hyper-Threading For Partitioned Thread Scheduling

Your CPU core isn't a single unit. Even putting aside things like L1 and L2 caches, and the registers where the core loads and stores values, modern processor cores have numerous functional units that do the actual work. These include things like Load/Store Units and Arithmetic Logic Units that perform simple math operations very quickly, and Floating Point Units that perform more complex math, the last of which have grown to be very large in modern CPUs with the introduction of 256-bit- and 512-bit-wide vector operations.

It's very rare that a single program thread can actually fill all of a processor's functional units with work. When a thread has to wait on a functional unit to complete a task for however-many cycles, the rest of the core is sitting idle, which is both wasted time and wasted power, as it's not like the core can clock down since part of it is currently working. Hyper-Threading was added as a way to try and mitigate this. By scheduling a second thread on the same core, the second thread's work can fill those "execution bubbles," at least in theory; sometimes, the two threads contend for resources and it actually hurts performance.
This is pretty rare on one of today's multi-core processors, though, because operating systems are smart enough to schedule busy threads on separate CPUs altogether. Windows is fully aware of the core topology of the chips it's running on, and it will try to avoid scheduling two demanding threads on the same CPU core. This does lead to the best performance, but as we noted above, it also isn't great for efficiency.

Contemporary CPUs are gaining core count rapidly. If you look at the top-end 10th-generation Core processor, it had ten cores. Compare that to the Core i9-13900K, which has some twenty-four CPU cores. Of course, those aren't exactly the same thing; the Core i9-10900K had ten Skylake cores, while the Core i9-13900K has eight Raptor Cove P-cores and then sixteen Gracemont E-cores. The idea is that performance-sensitive tasks can be scheduled on the P-cores while background and other tasks can be relegated to the significantly slower E-cores.
The presence of Hyper-Threading complicates this, though. It's true that there are times when a hyper-thread (the second thread on a core) is the best place to schedule an application thread. These are fairly rare circumstances, though, and most of the time these extra "logical cores" go entirely unused on a CPU like the Core i9-13900K. Despite that, they still occupy ports on the processor's "ring bus". Every extra port on the CPU's ring bus adds latency and complexity to the CPU. However, without Hyper-Threading, much of each P-core will sit idle most of the time. How to resolve this?
Intel's new solution might be the technique outlined in a patent called "Methods and apparatus to schedule parallel instructions using hybrid cores." The patent was published back in June, but it's only recently getting some attention around the web. Reading over the patent is fascinating, and as usual for patent applications, it's a fairly high-level overview of the technique, but it's enough to get the gist of what Intel intends.
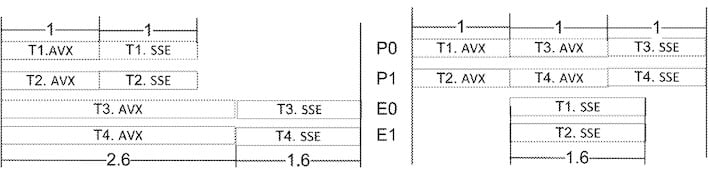
Basically, instead of scheduling on the application thread level, this new method analyzes the work required by a thread and then breaks application threads into segments using partitions. These partitioned threads are then scheduled onto processor cores based on their performance requirements. In other words, a program thread that is mostly simple ALU work but includes a crunchy AVX section may be scheduled onto an E-core, but have its AVX work thrown over to a P-core to make sure it gets completed within a certain time threshold.
The patent talks at length about the method, describing a self-tuning algorithm where the processor's own "Streamed Threading Circuitry" (described as a "Renting Unit" in leaks and likely an evolution of Intel's current Thread Director) logs the amount of time each partition takes to execute, and if the estimation for execution time was wrong, the processor will begin to schedule similar partitions on the the appropriate core type: E-cores if execution completed very quickly, or P-cores if it was very slow.
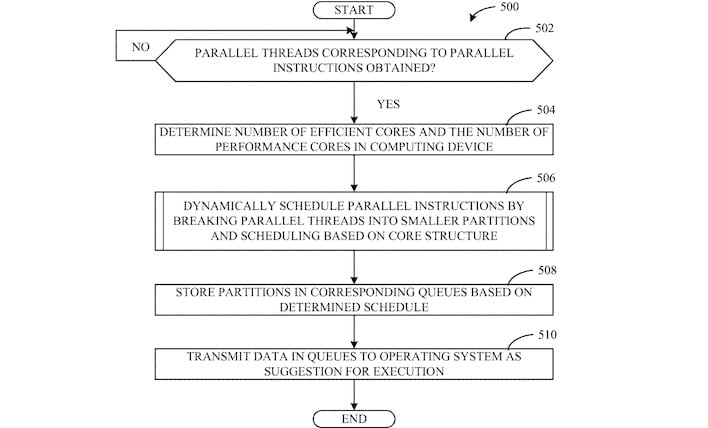
Interestingly, the patent describes the CPU's own scheduling hardware submitting these decisions as "suggestions" to the operating system. This implies to us that processors using this type of design will continue to be compatible with existing operating systems and other software—a concern when Intel is also talking about things like its X86S proposal that cuts legacy cruft and breaks compatibility with older software at a hardware level.
The proposal reminds us somewhat of the fascinating VISC proposal from Soft Machines back in 2014. We didn't cover that at the time because it sounded like pie-in-the-sky from an unknown startup, but Intel actually purchased the fledgling CPU design firm almost immediately after it first showed its VISC concept. That idea was to improve single-threaded execution by splitting the work across multiple cores at an instruction level. Sounds pretty familiar, doesn't it?
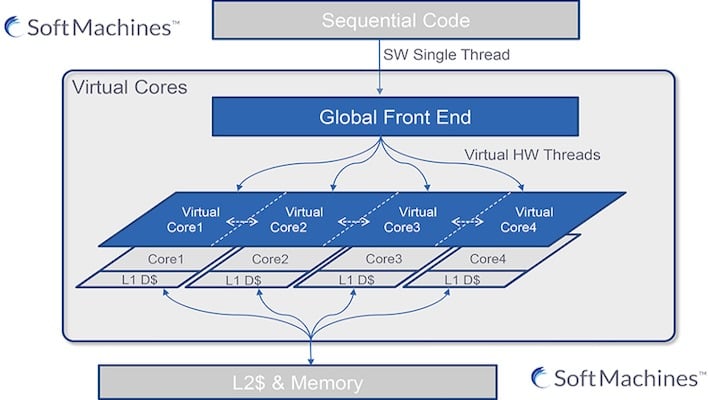
Based purely on our own analysis of the idea, if it works well, it seems like it could improve both processor efficiency as well as performance. Chunky threads could have work executed with even greater parallelism than was possible in the past, improving what we would currently consider "single-threaded" speed. Likewise, more of the processor could go idle more quickly, which would help power efficiency considerably.
If we take leakers at their word, this technology could appear as soon as next year with Intel's Arrow Lake processors that are expected to go head-to-head against AMD's Zen 5 architecture. AMD also seems to be doing interesting things with hybrid core architectures, so the competition should be quite fierce, and we can't wait.
