NVIDIA nForce 790i SLI Ultra and GeForce 9800 GX2

Like the nForce 680i and 780i SLI that came before it, the new nForce 790i SLI Ultra has support for Enhanced Performance Profiles, or EPP. EPP is a feature designed to maximize system performance by automatically tweaking memory and CPU frequencies, multipliers and voltages. The different with the nForce 790i SLI Ultra though, is that EPP - now up to revision 2.0 - supports DDR3 memory.
|
|
|
;)
The nForce 790i SLU Ultra's DDR3 Memory Interface
;) Like EPP, EPP 2.0 is an open memory standard that has been adopted by a number of motherboard and memory manufacturers. Enhanced Performance Profiles 2.0 increases performance by taking advantage of additional memory parameters added to the unused portion of a standard JEDEC Serial Presence Detect, or SPD. The JEDEC specification only calls for small amount of data to be stored in a standard SPD, which leaves a significant amount of unused space. EPP 2.0 takes advantage of this space to store specific information about the modules, like their maximum supported frequencies and timings.
Like EPP, EPP 2.0 is an open memory standard that has been adopted by a number of motherboard and memory manufacturers. Enhanced Performance Profiles 2.0 increases performance by taking advantage of additional memory parameters added to the unused portion of a standard JEDEC Serial Presence Detect, or SPD. The JEDEC specification only calls for small amount of data to be stored in a standard SPD, which leaves a significant amount of unused space. EPP 2.0 takes advantage of this space to store specific information about the modules, like their maximum supported frequencies and timings.
EPP 2.0 also needs motherboard support to function. To support EPP 2.0 a motherboard's BIOS has to be programmed to snoop the upper portion of the SPD to find the relevant configuration data. That data is then used in conjunction with a pre-determined set of parameters stored in the system BIOS to automatically tweak performance.
For example, if the EPP 2.0 data stored in the SPD states a particular memory kit is capable of running at 1800MHz with 7-7-7-20 timings at 2.0v, EPP 2.0 will automatically alter the processor's multiplier, the voltage and bus speed, along with the memory voltage, to get as close to the memory's rated speed as possible. EPP 2.0 can also be configured to overclock the processor by a user determined percentage to hit the memory's rated speed.
|
|
|
PWShort
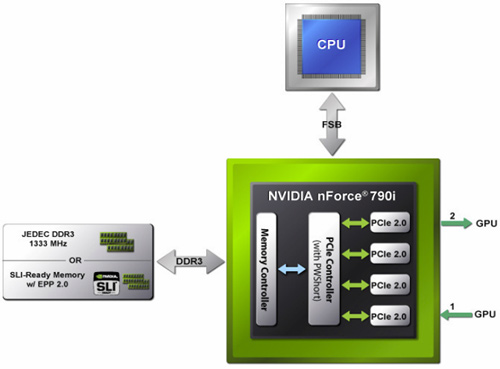
When we covered the nForce 780i SLI launch a few months back, we talked about the NF200 chip that brought the chipset's support for PCI Express 2.0. With the nForce 790i SLI, however, the NF200 has essentially been integrated into the MCP. Along with its PCI Express 2.0 interface, NVIDIA has also disclosed details regarding patented technology that we'll talk about here. Essentially, what NVIDIA has done is build-in a couple of fast paths inside the switch device, dedicated to optimizing mulit-GPU SLI transaction performance both back to the root CPU complex and peer-to-peer between GPUs

Broadcast
Specifically, there are two functional blocks as you'll note in the above diagrams, denoted as "Broadcast" and "PWShort". The Broadcast block provides a broadcast send mode for the root complex down to all GPUs in the system. This allows efficient transfer of data in one group transaction. PWShort, (which stands for Posted Write Short), is a dedicated cut-through mode for peer-to-peer communications between the GPUs, without the need to tap on upstream bandwidth to the CPU complex. What this means is that given the right workload, Broadcast and PWShort allow for faster data transfers too and from the GPUs.





