Intel 5th Gen Xeon Processors Debut: Emerald Rapids Benchmarks
SMHasher 1.1.0 Security Processing Benchmark

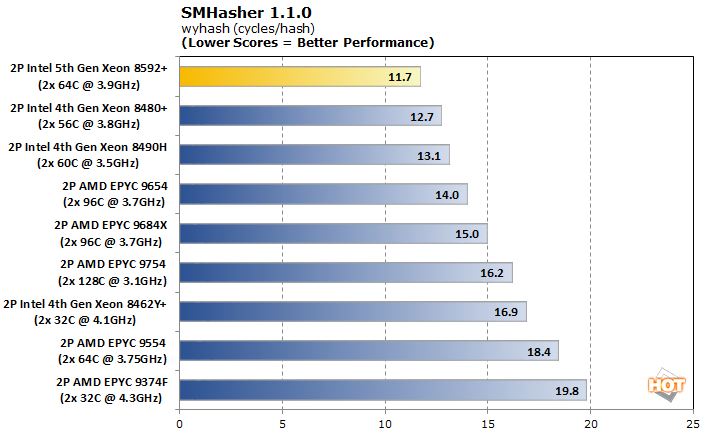
With AVX in full swing, Intel reigns supreme. Hashing is one of the most important cryptographic functions that servers in the datacenter perform, and the dual 64-core 5th generation Xeons are about 80% faster than AMD's dual 64-core configuration. Intel scores a clean sweep here both in raw megabytes hashed per second and in terms of efficiency with cycles per hash.
Intel Open Image Denoise 1.4.0 Benchmark
An important aspect of ray tracing is the denoising step which cleans up the image for a better-looking frame. Part of oneAPI, Intel Open Image Denoise is one such library to accomplish this which can be used not only for gaming, but also for animated features.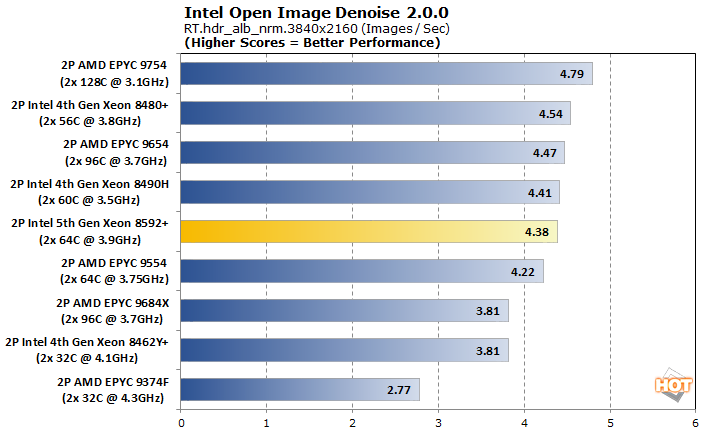
As part of Intel's oneAPI rendering toolkit, the Open Image Denoise algorithm exploits advanced instruction sets to wring the most performance out of a CPU. More cores generally help performance, at least a little bit, but this test can be thought of more as an AVX-512 workload. Genoa-based EPYC processors also support AVX-512 but the implementation is still a strength for Intel.
OneDNN 3.0.0 RNN Training And Inferencing Benchmark
OneDNN is an Intel-optimized open-source neural network library that is now part of oneAPI. Our testing looks at its performance in convolution across three data types: f32, u8u8f32, and bf16bf16bf16.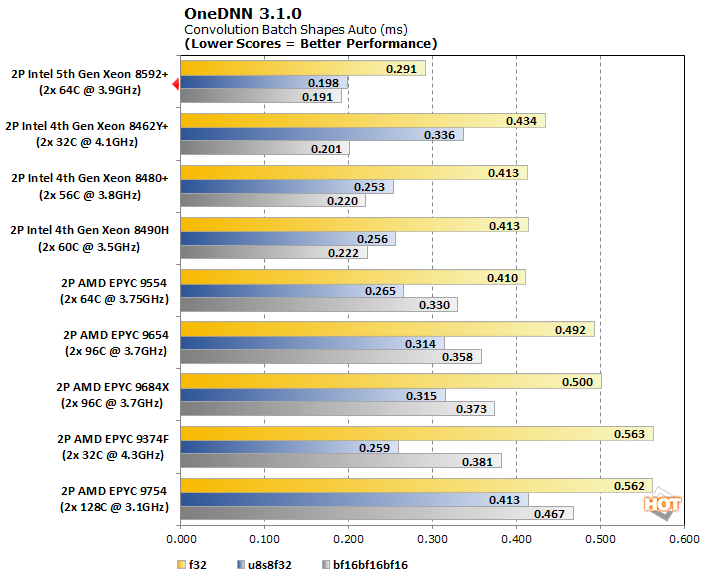
The machine learning enhancements that are part of Emerald Rapids give the Xeon Scalable 5th generation a truly epic leap in neural network training across each of the test's data types. The bfloat16 test in particular demonstrates the value of using smaller, high-range floating point values in training machine learning models. Models that require higher precision (e.g., larger) data types like 32-bit floating point values, will benefit the most. The Xeon 8592+ is nearly 40% faster than any other configuration in that test thanks to Intel's AI acceleration technology.
ASKAP 2.1.0 Convolutional Resampling
The Australian Square Kilometre Array Pathfinder (ASKAP) is a massive radio telescope complex in Western Australia. It is tasked with processing enormous datasets including the tConvolve algorithm here which performs convolutional resampling.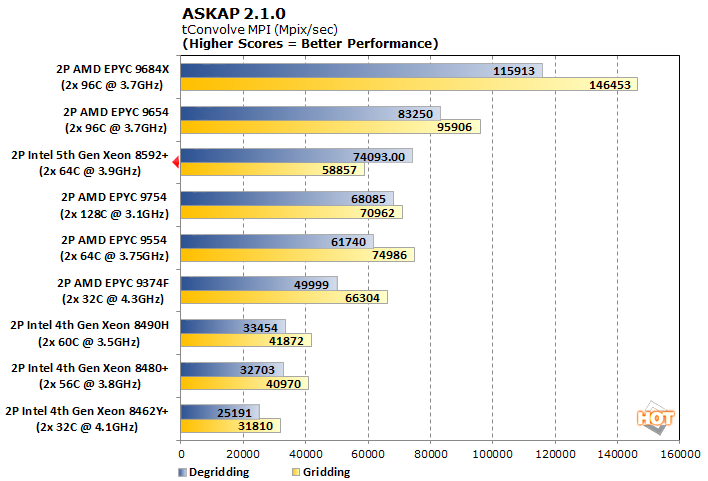
This is another test where more cores isn't always better, as the dual-128-core EPYC 9754 demonstrates, but AMD's V-cache is extremely helpful as the EPYC 9684X testbed shows. While AMD still dominates this benchmark, Intel's newest Xeon Scalable processors are about twice as fast when compared to the previous generation. Intel has moved from dead last in this benchmark to a rather competitive position, especially in the Degridding test.
OpenFOAM 1.2.0 Computational Fluid Dynamics
OpenFOAM is a free and open-source computational fluid dynamics program from the OpenFOAM foundation. We tested two aerodynamics models, the smaller-scale motorBike and the large-scale drivaerFastback.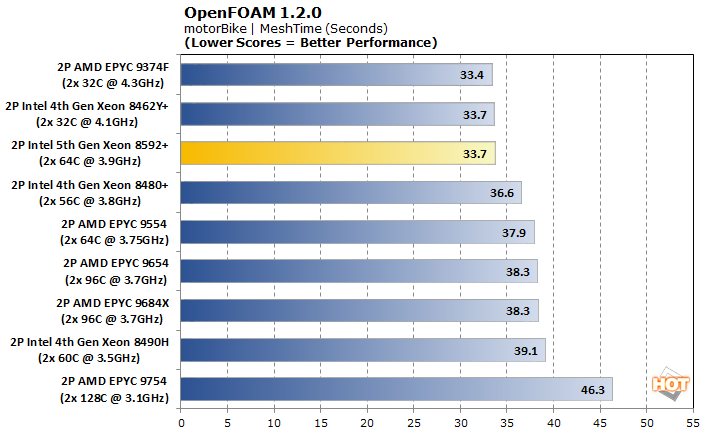
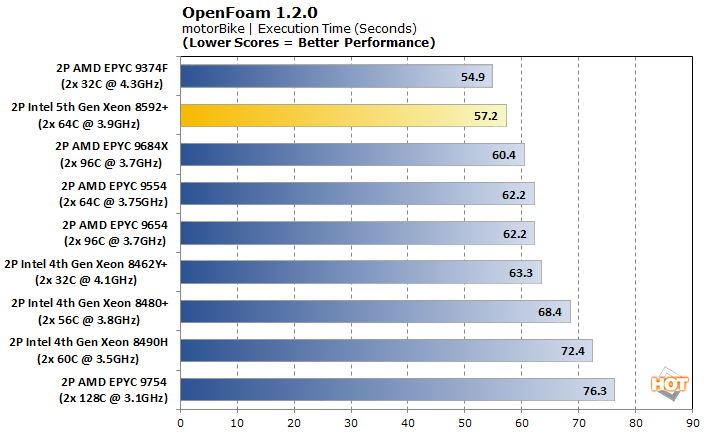
Starting with motorBike, the mesh times are favored on the lower core-count chips. The 32-core EPYC 9374F doesn't need any sort of interconnect for its cores to talk to one another, so the total lack of latency allows it to take first place. This also explains why the 32-core Xeon 8462Y+ is the fastest in the last generation. Overall the 64-core Xeon 8592+ acquits itself very nicely, with the second-lowest execution time and essentially ties at the top of the leaderboard for Mesh Time in this smaller test.
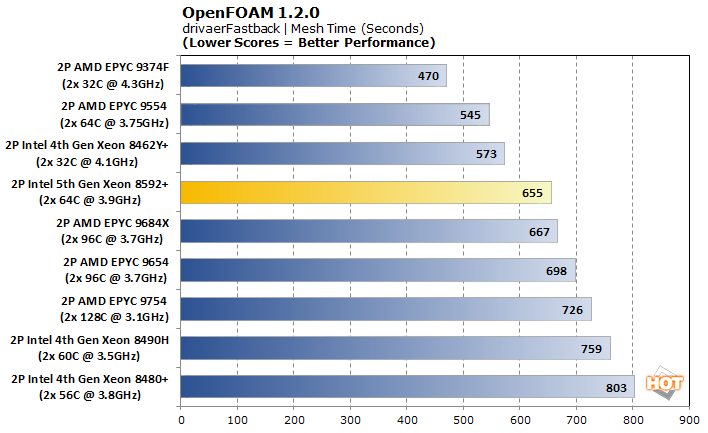
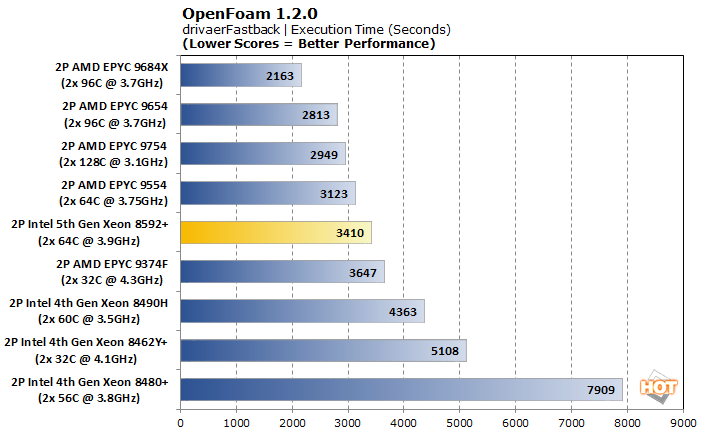
With a significantly larger model in drivaerFastback, the higher core count CPUs jump towards the top in execution time, and the V-cache of the EPYC 9684X gives it a solid win. Mesh time still favors the lower internal latencies of the lower-core CPUs, though Intel's gains generation-over-generation are still a significant 10%. Execution time shows the biggest strides, though, with the 5th generation is about about 22% faster than the best 4th gen system.
LAMMPS 1.4.0 Large Scale Atomic Simulation
The Large-scale Atomic/Molecular Massively Parallel Simulator is widely used for materials modeling in a range of fields, thanks in part to its open-source availability. This enables it to be adapted to all kinds of hardware and to be modified for new functionality.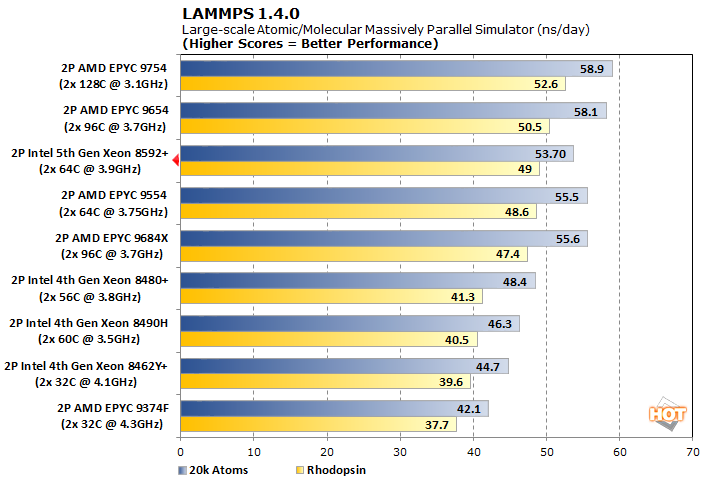
This is a pair of tests where more cores help to a point, but not as much as the increase in core count might suggest. Intel is sporting a 20% gain over its previous generation, which takes the latest Xeon Scalable processor from last place up towards the middle of the pack. The 5th Generation Xeon Scalable 8592+ edges out the 64-core EPYC 9554 in Rhodopsin and gives that advantage back in the 20k Atoms test. They're on roughly equal footing here.
Intel Memory Latency Tool
Emerald Rapids-based 5th Gen Xeon Scalable processors support faster memory configurations than Sapphire Rapids. Emerals Rapids supports DDR5-5600 speeds, whereas Sapphire Rapids tops out at DDR5-4800. While higher clocked memory typically offers more peak bandwidth, it often comes at the expense of latency, especially early on in a memory technology's lifetime. To test the memory performance characteristics of 5th Gen Xeons, Intel provided a memory latency testing tool, which which ran through a variety of workloads to suss out differences in memory peformance...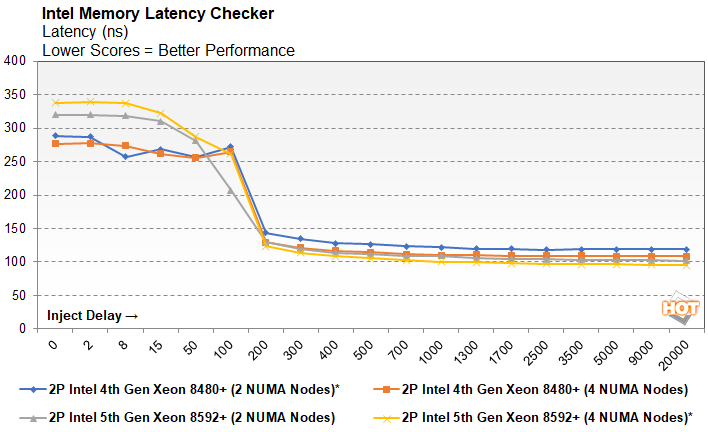
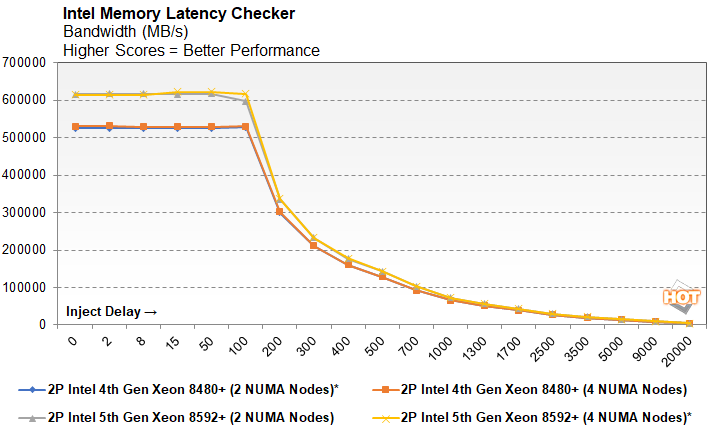
Intel's default configuration for the 4th generation of Xeon Scalable processors is to put each CPU in its own NUMA node, while the 5th generation defaults to splitting its CPUs in half with a pair of NUMA nodes a piece, for a total of four in our 2P system. To see what kind of effect the NUMA node configuration had on performance, we ran a couple of 4th and 5th Gen Xeon configurations set up for both 2 and 4 NUMA nodes. The point of the test above is to measure latency and bandwidth as demands increase. The tool injects a delay, measured in cycles, to simulate a load being placed on the system by other processes and measures the impact on bandwidth and response time. The delay doesn't stop the system from queueing up operations (the default results above measure sequential reads) and as a result, the latency actually decreases under a higher load while available bandwidth comensurately decreases.
Because the memory in our 4th generation testbed runs at 4800MT/s while the 5th generation CPUs utilize memory clocked at at 5600MT/s, bandwidth is higher across the board on Intel's newer platform. However, as the injected delay increases, the memory bandwidth takes a dive. Incidentally, using two or four NUMA nodes has a minimal but measurable impact on latency while leaving raw total bandwidth virtually unaffected. Communication across nodes does incur a latency penalty when hitting system RAM.

Raw bandwidth is more or less what you'd expect; faster memory has more bandwidth available to it. And again, the NUMA node configuration shows RAM bandwidth is pretty close in either configuration, but using more nodes allows a hair more bandwidth across a variety of workloads. As the ratio of reads to writes increases, so does the bandwidth; the biggest improvement comes when a system doesn't have to worry about bidirectional traffic.

Latency measured when one CPU needs to read data out of the other socket's L2 cache is significantly reduced by subdividing each CPU into a pair of NUMA nodes. The 4th Gen Xeon Scalable processors even benefits from an increase in NUMA nodes, even though the default configuration seems to put each CPU core tile into its own. Still, the 5th generation improves over its predecessor further with an accumulated difference of a 25% reduced latency when comparing default configurations.
Intel 5th Gen Xeon Scalable Final Thoughts And Conclusions
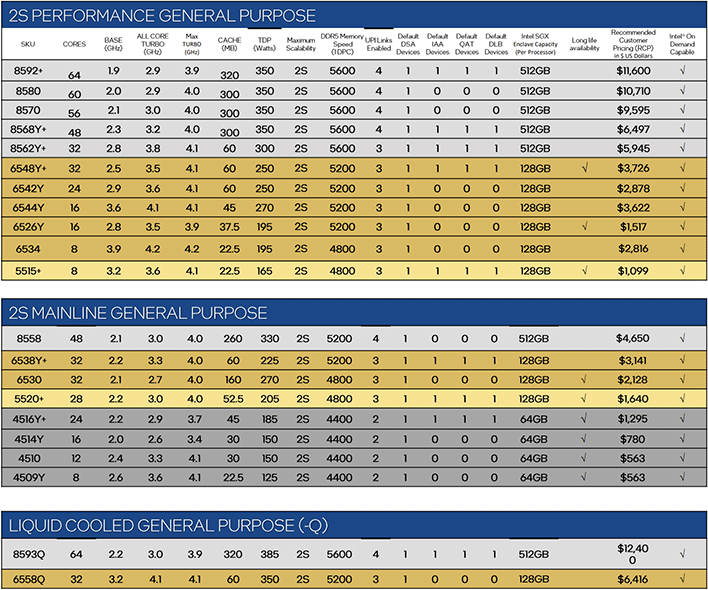
Intel’s 5th Gen Xeon Scalable “Emerald Rapids” processors are fundamentally similar to their 4th Gen cousins, but with more cores, more cache, higher clocks (for some models), and enhanced power efficiency, so he 5th Gen Xeons represent meaningful upgrades in a number of ways. The core technologies in each generation are similar, but the refinements in Emerald Rapids pay clear dividends in most workloads.
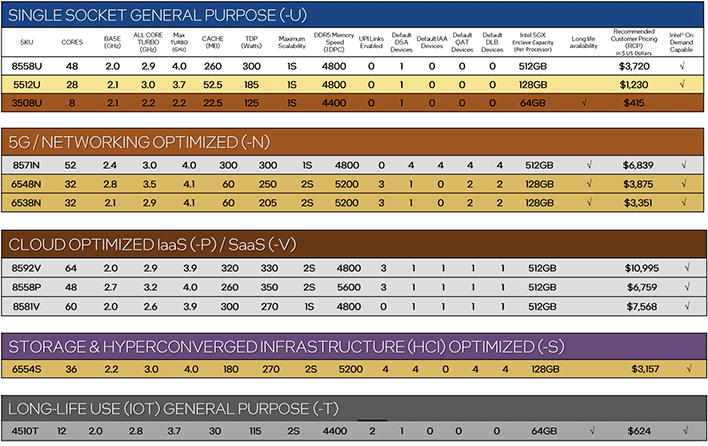
Intel is also simplifying the 5th Gen Xeon Scalable lineup. This time around there are 31 5th Gen Xeon Scalable models available with varying core counts, clocks, and cache configurations. Support for higher memory speeds also scales based on where the model falls in the stack. Like previous gen Xeon Scalable processors, Intel offers 5th Gen Xeon Scalable configurations targeting many applications, from cloud / 5G network optimized, to high-performance general purpose models. Unlike 4th Gen models, however, 5th Gen Xeon Scalable processors only support up to 2 sockets (vs. 8) and there are no HBM-equipped Xeon Max models. Because Emerald Rapids is soft of a mid-life kicker to an existing platform, it makes sense to limit configurations to the highest volume, less-specialized models.
Of course, over and above what’s listed in the tables above, Intel’s “On Demand” service model can further differentiate parts, based on which accelerators (if any) customers choose to enable. Like 4th Gen Xeons, customers that want any / more accelerators enabled will have to make an additional investment. Depending on your point of view, this can potentially give other customers a lower cost of entry, but those same customers that don’t utilize the specialized accelerators may be better served by a competitive EPYC configuration. On the flipside, those accelerators exist fully functional in Intel’s silicon, and they’ll just sit there dormant without an additional fee. Intel has accelerators for networking, dynamic load balancing, data streaming, in-memory analytics, and more, so it’s likely many customers would benefit by one or more of them.
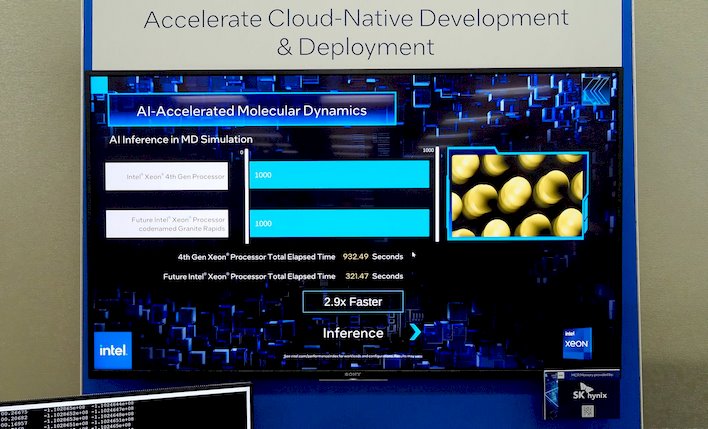
Granite Rapids Was Nearly 3X Faster Than Sapphire Rapids In An AI-Accelerated Molecular Dynamics Demo
While getting educated on Emerald Rapids, we were also fortunate enough to participate in a face-to-face with Intel CEO Pat Gelsinger, during which he was asked why the company is launching these processors, when a true, next-gen platform – i.e. Granite Rapids -- is already coming in 2024. Pat’s answer was a blunt, “…because it’s a better product.” And based on what we’ve seen, that is absolutely the case. 5th Gen Xeon Scalable Emerald Rapids processors are an incremental, but meaningful step forward for Intel and offer more value and performance to its data center customers.






