OpenAI's GPT-4 Model Can Ace The SAT, Pass The Bar, And Explain Memes

GPT-4 was just released by OpenAI today, and the company describes it as "the latest milestone" in deep learning. As a large AI model, it's essentially similar to GPT-3—it accepts text and images as input, and it can give text outputs in response. It's still quite far from the holy grail of a generalized AI, but as OpenAI remarks, it can "exhibit human-level performance" on a variety of professional and academic benchmarks.

Images in this post from OpenAI's blog.
How do you test a large AI model? Well, you could run a bunch of benchmarks intended for AI on it, and of course, OpenAI has done that. In common machine learning benchmarks like MMLU, HellaSwag, and HumanEval, GPT-4 outperforms its competitors (including its own previous generation) consistently, and sometimes considerably. GPT-4 can even outperform its previous-generation on MMLU when that test is translated into Punjabi language (while the GPT-3.5 model is testing in English.)
You can also test a large AI model by putting it through the same sort of tests you'd give a human. Tests like the Scholastic Aptitude Test (SAT), which most American students have to take before exiting high school. On the SAT Reading & Math portions, GPT-4 scored 1410 out of 1600, putting it around the 90th percentile of human students. On the more difficult Graduate Record Examination, GPT-4 did extremely well in the Quantitative and Verbal portions of the test, although it stumbled a bit on the Writing portion.

In programming tests, it did worse; the AI struggles with code, it seems. GPT-4 was able to get 31 out of 41 correct solutions in the "easy" Leetcode test, but got just 21/80 on the medium test and only 3 correct questions on the hard test. Meanwhile, its Codeforces rating is a measly 392, placing it below the 5th percentile of users.

Even still, the abilities of GPT-4 to understand and analyze inputs is almost unbelievable. This is demonstrated rather viscerally by the visual input test above. Presented with a meme and asked to explain it, the AI does exactly that, showing that it not only understands the text in the image as well as the image data, but the context of the joke, and why it is funny. It's an incredible step forward for multi-modal AI, and extremely impressive.
Much of the work on the model since the ChatGPT-fuelled explosion in GPT-3's popularity has been in the arenas of "steerability" and risk mitigation. Steerability refers to the ability of the operator to define the AI's behavior with a "system message" delivered before user interaction begins. As examples of such a definition, OpenAI presents GPT-4 responding as a Socratic tutor, as a Shakespearean pirate, and exclusively in JSON format.
The latter idea is easier to explain. In essence, using an AI model like this always carries risk that it could present "hallucinated" or simply incorrect information; OpenAI presents the examples of "generating harmful advice, buggy code, or inaccurate information." You've probably seen viral images going around the web of people doing exactly those things with ChatGPT.
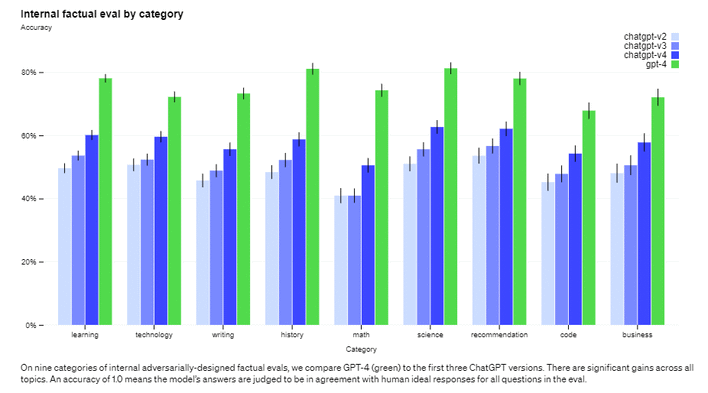
This kind of training has the potential to make the AI somewhat less useful, but being that it is likely being developed with the intention of being used as a public-facing commercial service, these sorts of limitations are ultimately to be expected, and likely to the benefit of society in the long run. OpenAI admits that there are still "jailbreaks" like "DAN" (or "Does Anything Now") that can be used to override these guidelines, anyway.
If you're interested in using GPT-4, you could be out of luck for a little while. Though the AI is "released", access to the API is only available through a waitlist that's likely to be quite long. However, you can have a chat with the AI if you'd like—it's available in a limited fashion to ChatGPT Plus subscribers. Head over to OpenAI's website to check it out, or read the full blog post talking about GPT-4's advancements.
