DeepMind's AlphaTensor AI Tackles Complex Math In A Way Gamers Will Relate To

Reinforcement learning broadly describes techniques that use rewards and penalties to guide an AI model through a complex task. A human analogy could be playing any game with a ranking system. Better play (e.g. winning games) is rewarded by moving up the leaderboard while mistakes are met with a drop in rank. Along the way, players will try different tactics and strategies to adapt to what opponents are doing. Of course, some humans may not be bothered to care about a ladder rank, but AI models can be compelled with software.
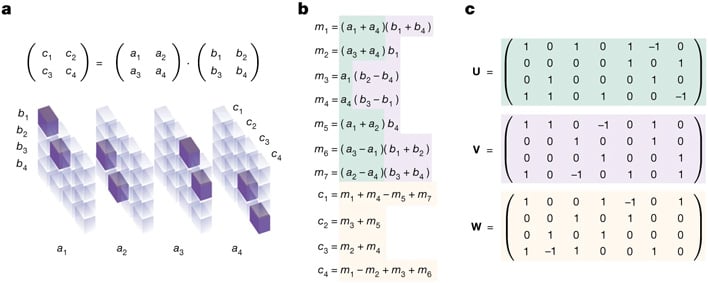
AlphaTensor is an AI model based on AlphaZero which is tasked with discovering algorithms to solve arbitrary matrix multiplication problems. Matrix multiplications are used to describe transformations in space and the matrices represent a mathematical concept called a tensor, the general term for scalars and vectors. Tensor math is at the heart of linear algebra and has applications in various fields from materials science to machine learning itself.
Matrix multiplications are solved according to specific rules and processes. Like much of math, there are optimizations that can be made to solve these problems in fewer and fewer steps. The refined algorithms enable larger matrix multiplications to be completed at feasible timescales.
AlphaTensor is presented with a game in the form of a single player puzzle. The board consists of a grid of numbers representing a 3D Tensor, which AlphaTensor is then tasked with reducing to zeros through a series of allowable moves, comprised of matrix multiplications. The possible moveset is staggeringly massive, exceeding games like chess and Go by several factors.
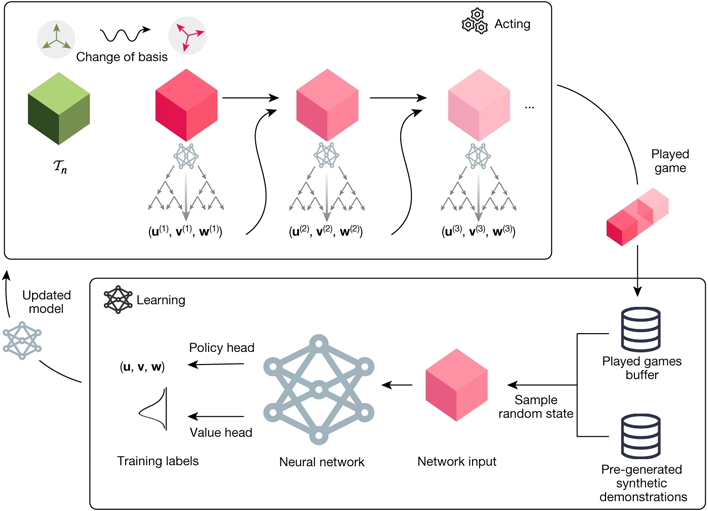
The AI uses Monte Carlo tree searches (MCTS) to plan its moves. This is effectively the same system used by AlphaZero to master chess and Go. With MCTS, the AI player looks at a sample of potential moves whose outcomes are tracked as a distribution of potential success. Rounds of the game are capped to a certain number of runs to avoid unnecessarily long games, but successful matches are fed back in to improve the network’s decisionmaking parameters.
Co-author Hussein Fawzi told Nature, “AlphaTensor embeds no human intuition about matrix multiplication,” so “the agent in some sense needs to build its own knowledge about the problem from scratch.” Through this feedback, AlphaTensor learns which moves are more likely to yield success, and successful it has been. In matrix sizes up to 5 x 5 pairs, AlphaTensor has matched or exceeded the efficiency of known algorithms in terms of steps.

Specifically, AlphaTensor has discovered a 47 step solution to paired 4 x 4 matrix multiplication which improves on the known 49 step solution which was found in 1969. It also shaved a couple steps off of paired 5 x 5 matrix multiplication, reducing 98 steps to 96. Its enhancements also extended to a few asymmetrically sized matrix multiplications, with better ways of solving 3 x 4 times 4 x 5 matrices, 4 x 4 times 4 x 5 matrices, and 4 x 5 times 5 x 5 matrices, the last of which it accomplished in four fewer steps than known methods.
The researchers note that the initial predefined moveset sampling does present a limitation. It is possible that more efficient algorithms could be derived from starting moves that are excluded at the start. Apart from brute forcing every possible move—which is computationally expensive—the researchers believe they could adapt AlphaTensor to find better starting sets itself. An AI operating on the fundamental math it is built from and optimizing its conditions? Maybe this is starting to sound like the singularity.
In reality though, it is easy to draw parallels between AlphaTensor learning to solve these immense problems and a fledgling Starcraft player, which DeepMind's AI has coincidentally excelled at too. Through iteration, it learns which moves will maximize its chances of success and which are more likely to end in failure—like having a swarm of zerglings get roasted by the opponent’s clump of fire-spewing hellbats. The zerg player can try sneaky run-bys in future matches to exploit the hellbat’s lack of mobility in future matches rather than engage in a direct fight. Matrix multiplication may not be as thrilling, but the underpinning process the AI uses to learn is all the same.
