BAM! NVIDIA And IBM Partner To Let GPUs Talk Directly To SSDs For A Major Performance Lift

The thing is, despite their differences, the essential function of both is to take input data and compute on it for output. In a typical system, storage I/O is connected to the CPU and the GPU is treated as a co-processor or sub-processor; when the GPU needs data, it has to get it from the CPU first. That's not really a problem per se, except that in some modern systems the GPU is doing much more work than the CPU is. Ultimately, in that case, using the CPU to orchestrate everything collectively can reduce the performance of both processors.
Microsoft's trying to fix this with its DirectStorage API, but that isn't quite ready for prime time, it seems—and it's exclusive to Windows, of course. AMD gave the issue a shot back in 2017, but the high price of the Radeon Pro SSG combined with the proprietary API requirement meant that product was basically dead on arrival.

Well, nowhere is the GPU dominant over the CPU like in supercomputing servers, where the "accelerators" (in many cases GPUs) do the overwhelming majority of the work. Naturally NVIDIA, who makes most of its money selling these accelerators, has quite an interest in accelerating GPU I/O throughput as well. Team Green, in collaboration with Big Blue as well as some folks from Stanford and the University of Buffalo, seem to have come up with another method for solving this problem, and they've given it a wonderfully-evocative name: BAM. However, the technology isn't quite a nod to Emril Lagasse, as you might expect.
BAM, stylized also as BaM, stands for "Big Accelerator Memory." Put simply, it's a software-based approach to move things that would normally be done on the CPU to GPU cores. This allows the "accelerators" in servers and HPC systems to snatch data directly from RAM and SSD storage without needing the CPU's approval first, thus speeding up access dramatically and lowering overhead.
Skipping the CPU has a lot of other advantages besides freeing up said CPU for other tasks. The GPU's massive parallel processing capability can be leveraged to parallelize storage access and defeat historical hurdles that arise from virtual address translation and serialization issues.

The researchers were able to demonstrate BAM using a prototype system equipped with off-the-shelf GPUs and SSDs running Linux. The authors say that the limitation of previous attempts to create such a structure was that they all relied on the CPU for orchestration, while BAM allows the GPU to operate nearly independently from the host CPU.
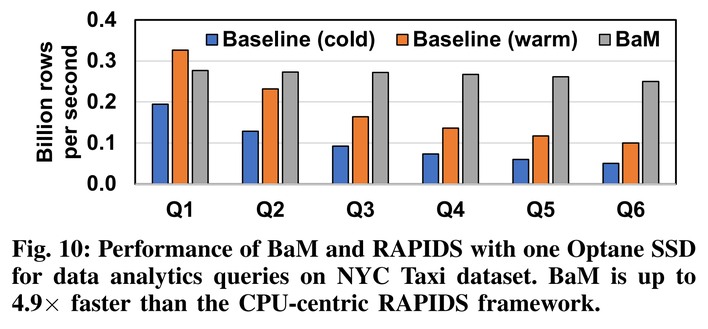
Frankly, as we're not HPC researchers, a lot of the information in the paper goes over our heads, but the end results are that BAM sees a 4.9x performance uplift in the best case against extant techniques for accelerating GPU I/O. If you'd like to dig down into the gritty details, you can find the paper at Cornell University's Arxiv library.
Thanks to The Register for the tip.
