NVIDIA's TensorRT AI Model Now Runs On All GeForce RTX 30 And 40 GPUs With 8GB+ Of RAM

TensorRT-LLM will soon be able to work with OpenAI’s Chat API using a new wrapper. This will enable developers to work on projects and applications locally on their Windows 11 PC instead of the cloud. This is a big boon for individuals or companies who were hesitant to use OpenAI, because the sensitivity of the data their projects employed didn’t allow for a workflow that included the cloud.
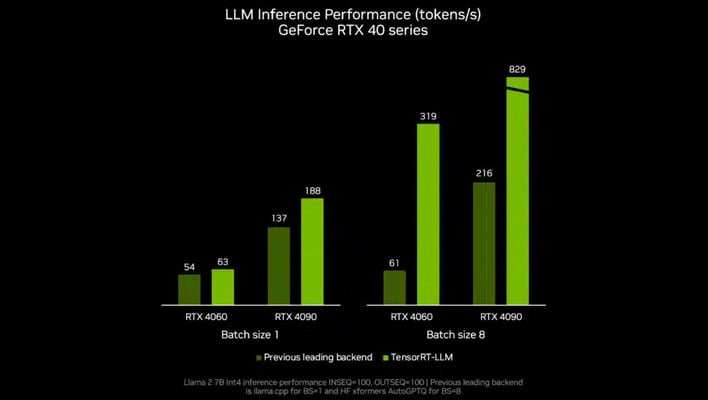
According to NVIDIA, “The next TensorRT-LLM release, v0.6.0 coming later this month, will bring improved inference performance — up to 5x faster — and enable support for additional popular LLMs, including the new Mistral 7B and Nemotron-3 8B. Versions of these LLMs will run on any GeForce RTX 30 Series and 40 Series GPU with 8GB of RAM or more.” NVIDIA states that there are 100 million PCs worldwide that contain the RTX GPUs necessary to take advantage of the update.
These advancements are thanks to the close collaboration between NVIDIA and Microsoft. The two companies have been able to increase performance of Llama on RTX with the DirectML API. It’s because of this work that developers are now more easily able to deploy AI models using a cross-vendor API.
Developers and AI enthusiasts will be able to check out these latest optimizations by downloading the latest ONNX runtime, along with installing the latest driver from Nvidia, on November 21st.
