NVIDIA Unveils Rubin CPX Amidst Chart-Topping Blackwell Ultra MLPerf Results

Today at the AI Infrastructure Summit, NVIDIA made a couple of pretty big announcements. The first was that the company ran MLPerf on its bleeding-edge GB300 Blackwell Ultra GPUs and basically set every record for AI inference performance. This wasn't just due to the new hardware, but also due to changes in the software architecture.
NVIDIA Dominated MLPerf Inference Benchmarks With Blackwell Ultra
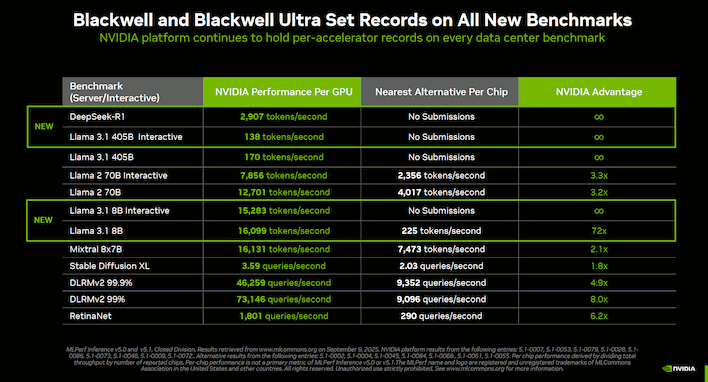
NVIDIA explains that new techniques were involved in setting these records, like the 'extensive' use of the NVFP4 format that preserves accuracy while radically reducing the performance and memory demands of huge AI models, like DeepSeek-R1. NVIDIA says that it also made use of new parallelism techniques, including specialized "expert parallelism" for the Mixture of Experts portion of execution, and then "data parallelism" for the attention mechanism. Doing this kind of split requires careful workload balancing, so the company developed "Attention Data Parallelism Balance" as a method to "intelligently distribute the context query."
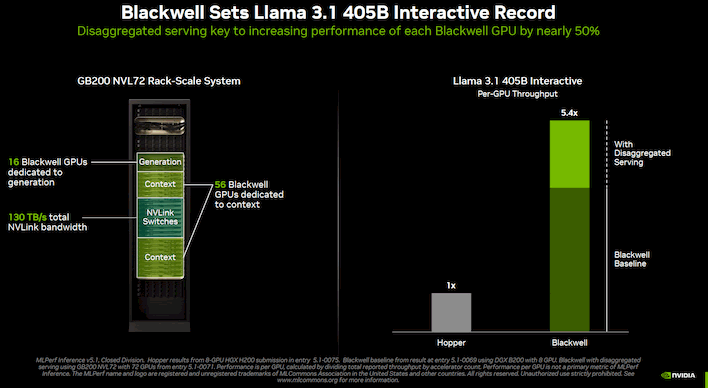
The AI leader also talks about "Disaggregated Serving". This is an interesting technique where the AI inference workload is split between two pools of GPUs, because inference is really two tasks. As NVIDIA explains, the first step is the "Context/Prefill" step where the model processes the input prompt, and then the second step is the "Decode/Generation" step, where the model generates its response.
The first part is extremely compute-intensive, but the latter part is primarily memory-bound, and because of these disparate performance characteristics, it doesn't actually make sense to run them on the same GPUs. According to NVIDIA, splitting apart the workload this way resulted in a "nearly 1.5x increase" in throughput on a per-GPU basis, allowing the Blackwell machines to achieve 5.4x the performance of Hopper systems that weren't configured this way.
NVIDIA Rubin CPX For Massive Context Inference
Given that understanding of inference as being two separate workloads, it makes sense that NVIDIA would pair that announcement with this one: the company also revealed the upcoming "Rubin CPX" GPU. Rubin CPX is quite a different chip from the Rubin GPU we've already seen; rather than expensive HBM3e memory, it uses GDDR7. It also includes video encoders on-chip for use with generative video AI. Where the standard Rubin GPU is versatile and boasts massive memory bandwidth, Rubin CPX is instead designed for what NVIDIA calls "massive-context inference."
"Context," of course, is the data that you're feeding the neural network, and it includes prompts, conversation history, and things of that nature. The idea is basically that the compute-dense Rubin CPX GPUs can chew through dense context workloads rapidly while the full-fat Rubin GPUs crunch the generative workload and generate the tokens. NVIDIA says that exponent operations are three times faster on Rubin CPX versus GB300, and that the chip can crank out 30 petaFLOPS of tensor compute in the NVFP4 format.
Along with the new chip, NVIDIA's announcing a new rack that incorporates it. Where the standard Vera Rubin NVL144 will come with 72 Rubin GPU packages, 36 Vera CPUs, and fully 3.6 exaFLOPS of NVFP4-format compute, the upgraded "Vera Rubin NVL144 CPX" will apparently add eight Rubin CPX chips to every single compute tray. This boosts the NVFP4 compute of the full rack to over 8 exaFLOPS, which would have been considered a truly preposterous number just a couple of years ago.
NVIDIA also announced an upcoming dual-rack solution that uses standard Vera Rubin NVL144 compute trays in one rack along with "Vera Rubin CPX" compute trays that do not include the standard Rubin GPUs. In other words, you have one rack of a standard Vera Rubin NVL144 system, and then a second rack that is only Vera CPUs and Rubin CPX GPUs. This will increase the total memory capacity to 150 TB, and in theory should be even faster than the combined "VR NVL144 CPX" version, although NVIDIA quotes the same "8 EF" NVFP4 throughput number.
The standard Vera Rubin NVL144 systems are still slated for the second half of next year, while the massive Rubin Ultra NVL576 machines aren't coming until 2027. However, the newly-announced Vera Rubin NVL144 CPX and the dual-rack solution should be available by the end of next year.
