Cloudflare Exposes Perplexity's Deceptive Web Crawling Tactics

Most websites have no-crawl directives, which are meant to checkmate the activities of website crawlers by specifying which part of a website they are allowed to crawl. A good example of such a website's no-crawl directive is robots.txt, which a text document in a website's root directory that contains a list of rules for the activities of website crawlers.
Just like Google crawlers need website crawlers (Googlebot) to read webpages and present content for Google search users, Perplexity also uses its website crawler (PerplexityBot) to access website content. From an ethical point of view, all crawlers should respect robots.txt regulations and other guidelines since most websites have parts where crawling is disallowed. Cloudflare alleges that whenever PerplexityBot is presented with a rule to disallow crawling on a website, it uses a sneaky tactic to circumvent these rules and crawls the website forcefully.
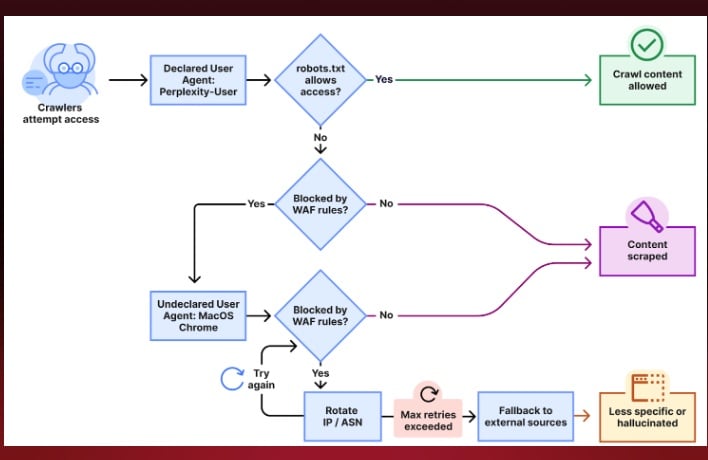
Cloudflare also reportedly discovered strong evidence suggesting that Perplexity modifies its user agents. A user agent is more like a string or name a website uses to request web pages from web servers. So whenever Perplexity's user agent is blocked from accessing a website, it allegedly impersonates a random user by using a generic user agent.
If you examine the table below, you will see the difference in user agents when Perplexity uses its official web crawler and when it allegedly uses an undeclared one to impersonate a random Google Chrome user on a macOS operating system.

Concerns that companies use unauthorized content to train their AI models continue to grow. For instance, last year, Reddit told Microsoft to pay up to scrape its data or be blocked. This recent discovery fuels the widespread concern that major AI companies publicly commit to carrying out ethical practices, while allegedly practicing the opposite.
Images courtesy of Cloudflare