Intel Refutes AMD's Xeon AI Performance Compare Vs EPYC Turin [UPDATED]


This is the slide in question, where AMD compares its upcoming EPYC Turin processors against Intel's extant Xeon Platinum 8592+ CPUs. These chips are part of the Emerald Rapids family, which is itself based on the same technology found in Sapphire Rapids. That is to say, these $11,600 CPUs come strapped with 64 Raptor Cove CPU cores clocked at up to 3.9 GHz: serious hardware for server systems.
AMD claims that a pair of EPYC Turin processors can outpace a pair of Xeon Platinum 8592+ chips by 5.4x when running a Llama 2-based chatbot. The performance is measured in "tokens per second," which is a measure of how fast the chatbot can process text input and deliver text output. However, Intel complains that AMD didn't disclose its software configuration used for this testing, and says that its own testing has produced a very different result:
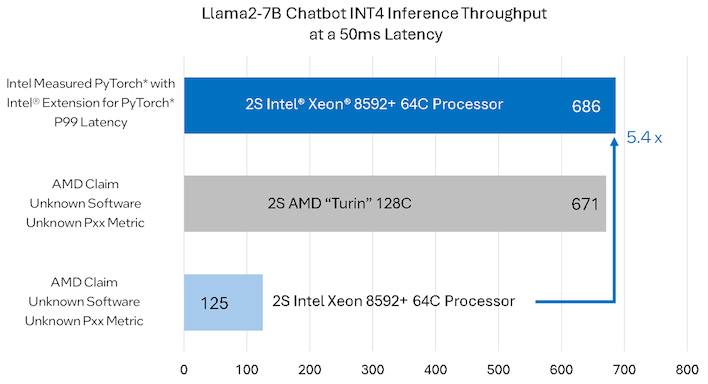
Indeed, Intel says that a pair of Xeon Platinum 8529+ chips can actually beat the result that AMD gave for the upcoming EPYC Turin CPUs in what it thinks is the same workload. Intel is understandably aggressive about pointing out that these results don't require obscure in-house optimizations or tweaks, but rather are achievable using publicly-available software. In other words, without saying as much, Intel is claiming that AMD may have (intentionally or unintentionally) presented an unfair comparison.
It's worth noting that if you go to HuggingFace, download the Llama2-7B model that AMD used for testing, and then set it up with a basic PyTorch environment, you won't get the kind of performance Intel is showing here. However, it's not difficult to see this kind of speed. All you have to do is install the Intel Extension for PyTorch, for which there is already a handy-dandy guide on Github.
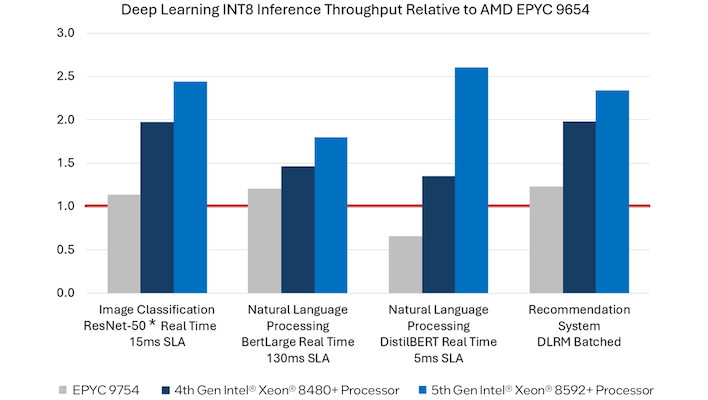
Intel goes on to compare its current and previous-generation hardware against AMD's EPYC processors. This chart is a little confusing; the red bar at 1.0 represents an EPYC 9654 96-core "Genoa" (Zen 4) CPU, while the grey bar represents an EPYC 9754 128-core "Bergamo" (Zen 4C) CPU. Intel shows itself clearly dominating in all kinds of AI workloads thanks to its efforts in software optimization.
One of the biggest challenges facing AI right now is how cumbersome these implementations can be. It is very easy to set up an AI model and get substandard performance because you didn't install the correct optimization package. I experienced this myself with Stable Diffusion, where setting up a package that includes optimizations for GeForce GPUs radically improved performance and reduced VRAM usage. It's not as simple as ticking a "use optimizations" checkbox in a GUI—though it probably should be. And may be one day.
As such, we have no doubt that AMD's results are real, likely for a naive configuration of Llama-7B, but we also have no doubt that Intel's performance claims are completely valid as well. Of course, we don't have all of this server hardware on hand to test these claims for ourselves, but they pass the sniff test. Intel's been talking up the huge gains from its Intel Extension for PyTorch for months, and the difference in the two benchmarks is right in line with those results.
Update June 17th: AMD has issued a response to Intel's assertions. According to AMD, the software library used by Intel to achieve this performance on Emerald Rapids was not actually available at the time that it performed its testing. The full statement from AMD is as follows:
At Computex, AMD highlighted the leadership performance of 'Turin' on AI workloads compared to 5th gen Intel Xeon processors using the most up-to-date, publicly available software available at the time for both AMD and our competitor. The data for "Emerald Rapids" that Intel highlighted in their blog uses a software library that was released on June 7, after our Computex event. It is also important to note the new software stack was only used for the Intel platform and the performance optimizations were not applied to the AMD platform. 4th Gen EPYC CPUs continue to be the performance leader, and we expect "Turin" to remain deliver leadership performance across a broad range of workloads when we launch later this year.
